Java集合
Iterator
集合中的顶级接口,源代码如下
1 | public interface Iterator<E> { |
包含2个动态方法
循环的时候要先调用hasNext进行判断,然后再调用next
实例1:Iterator遍历
通过操作迭代器来进行集合的遍历
集合中的任何数据结构,都可以使用foreach代替iterator循环。
原因是Collection接口扩展了Iterable接口
1 | public static void main(String[] args) { |
实例2:Iterator删除
Iterator 类似于一个指针,或者是SQL中的一个游标:在执行查找操作的同时,迭代器的位置会随之向前移动。可以通过next方法移动到下一个元素
1 | public static void main(String[] args) { |
实例3:随机序列产生器
1 | /** |
总结
从上述实例中可以看出,Iterator接口只具有
遍历和删除元素的功能Collection接口
继承了Iterable接口,并且提供了查询、判断等等的扩展功能AbstractCollection实现了Collection方法,相当于提供了默认的方法,如果子集合中有更高效的实现可以交给子类提供。
- 但是java8以后接口引入了
default,这种方式应该交给default方法,充当动态方法,允许子类重写 - Abstract方法必须先被继承后,才能够实例化;主要用于当一个类/接口不足以描述一个对象的时候的补充手段,相当于提供默认的实现
- Abstract方法,一般用于
模板方法设计模式,提供通用的总体算法骨架 以及 具体的业务抽象方法(该方法由子类来实现)
- 但是java8以后接口引入了
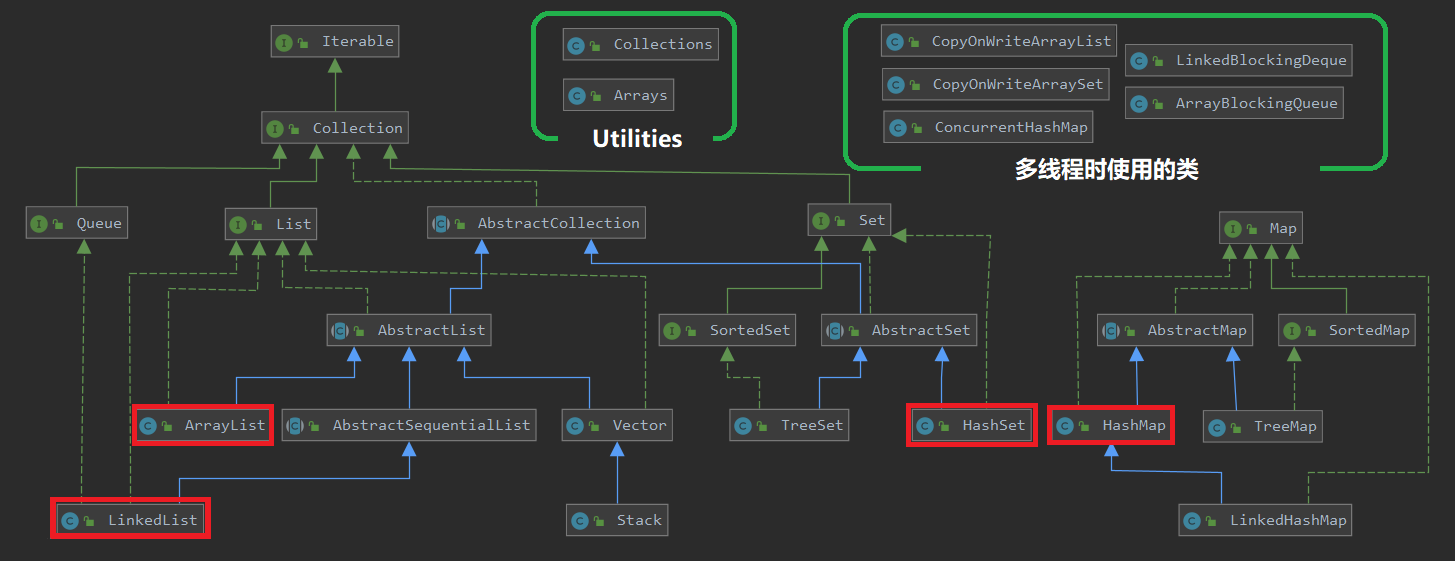
容器框架图
容器:用于容纳一组对象,不能容纳非对象类型,要能够增删改与遍历
容器 Collection 关系图
链表
LinkedList
- 优点:插入、删除元素的开销小
- 缺点:无法随机读取元素
- 场景:适用于查询少、操作多的场景
Java中的链表都是双向链表
1 | public static void main(String[] args) { |
散列集
适用于快速查找对象,并且不关心集合中元素顺序的场景
1 | public static void main(String[] args) { |
树集
是一个有序集合,输入一个任意顺序的元素,在遍历时会自动按照排序后的顺序呈现
1 | public static void main(String[] args) { |
映射
key-value存储的数据结构,指两组数据的映射关系
通过get()方法获取值,通过put方法设置值,通过remove方法删除值
TreeMap通过一定的顺序来组织元素,而HashMap里的元素则是无序的
TreeMap实例
1 | public static void main(String[] args) { |
链接散列集与映射
#TODO# LinkedHashSet & LinkedHashMap
实现LRU缓存
LRU(Least Recently Used)缓存:最近最少使用,页面被置换
为什么选择LinkedHashMap
- 链表能够实现队列,完成先进先出的逻辑
- <K,V>的映射能够通过Key来索引数据
1 | /** |
HashMap & HashTable
#TODO# HashMap & HashTable
容器的工厂方法
Java9 新特性:of与ofEntries
1 | public static void main(String[] args) { |
注意:工厂方法创建出来的集合对象都是不可变的,但是以下方式可以构造一个可变的集合
var list = new ArrayList<>(List.of(1,2,3,4,5));
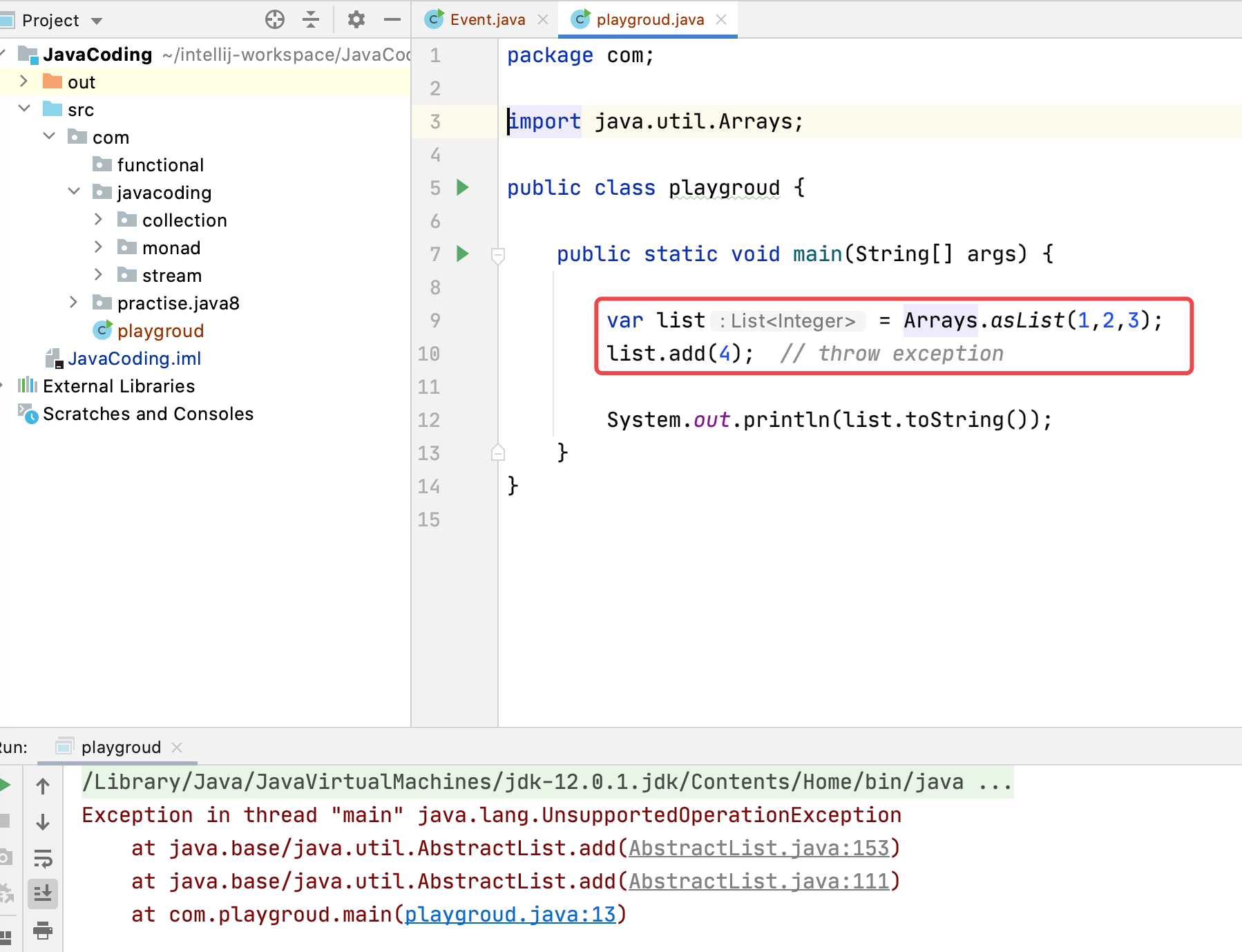
Arrays.asList
Arrays.asList 被称为不可变集合,该集合中元素可以更改,但是大小不可变
1.通过 Arrays.asList() 方法构造出来的list,不能执行add()和remove()。
这里的list,并非 java.util.ArrayList,它没有重写父类AbstractList的方法。
2.如果使用Arrays.asList()生成新的数组,那么修改的内容也会同步影响到旧数组上。
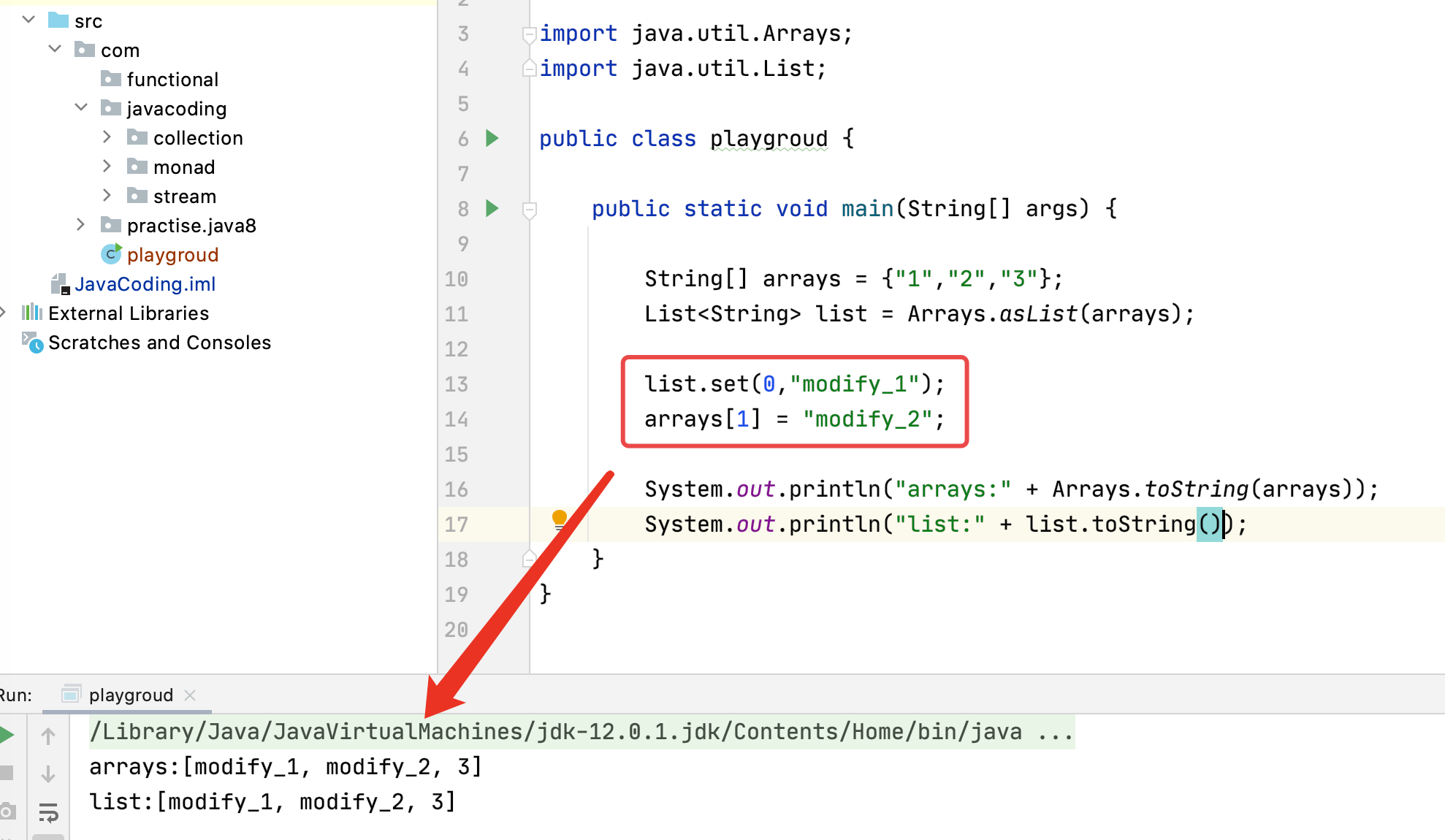
总结:尽量用于测试,不要用于开发业务上。