Oracle技术分享 - DAY 3
容器数据库
【注意】容器数据库(多租户结构)为19c新特性
查看容器数据库(PDB,pluggable database,即可插拔数据库)
show pdbs;
执行结果
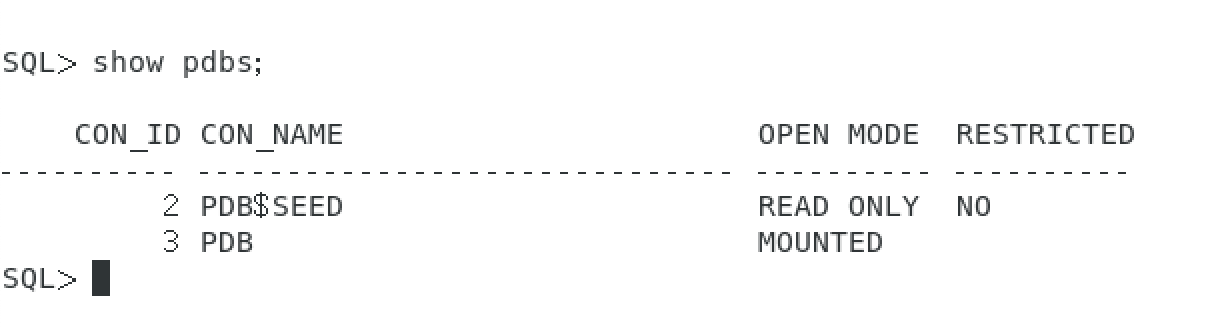
- PDB$SEED:种子数据库,是克隆的模版容器数据库
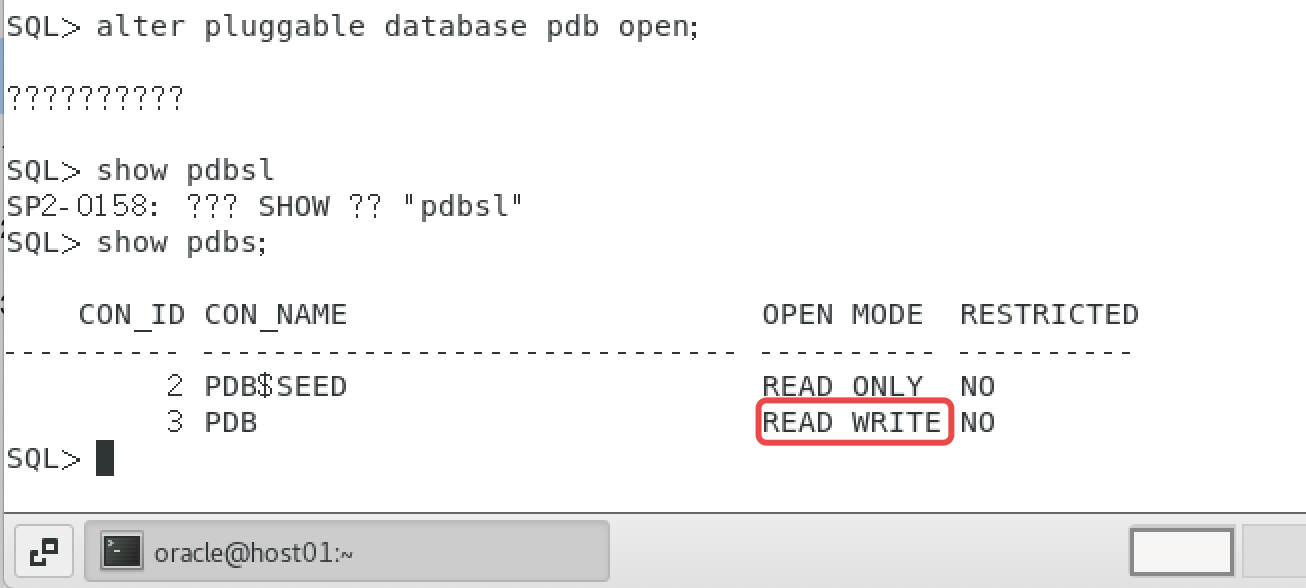
启动PDB
alter pluggable database pdb open;
启动结果
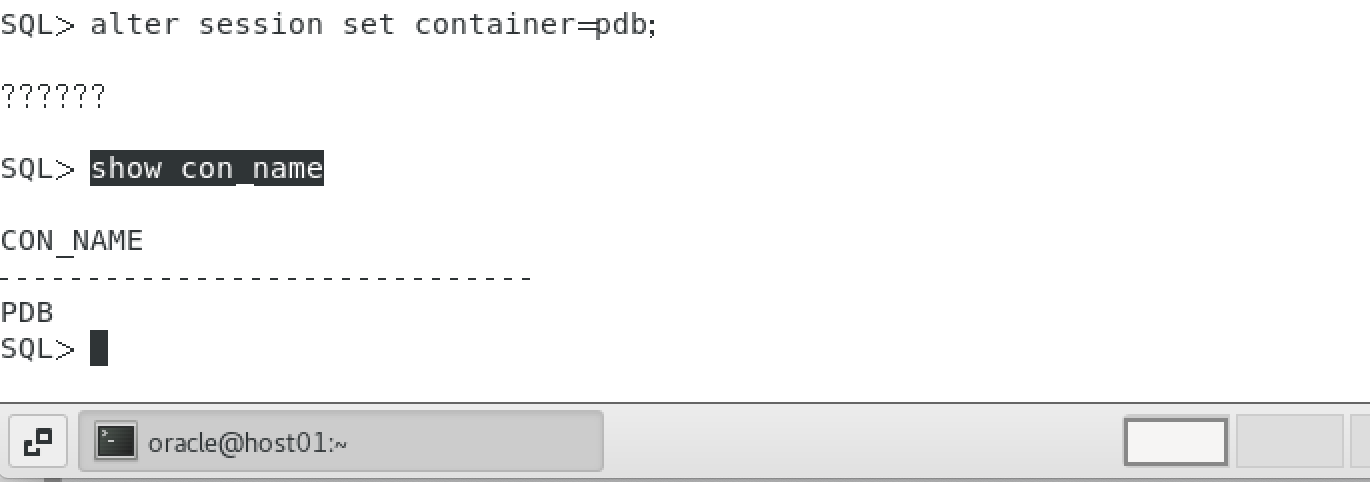
进入容器数据库
alter session set container=pdb;
查看当前容器
show con_name
结果:
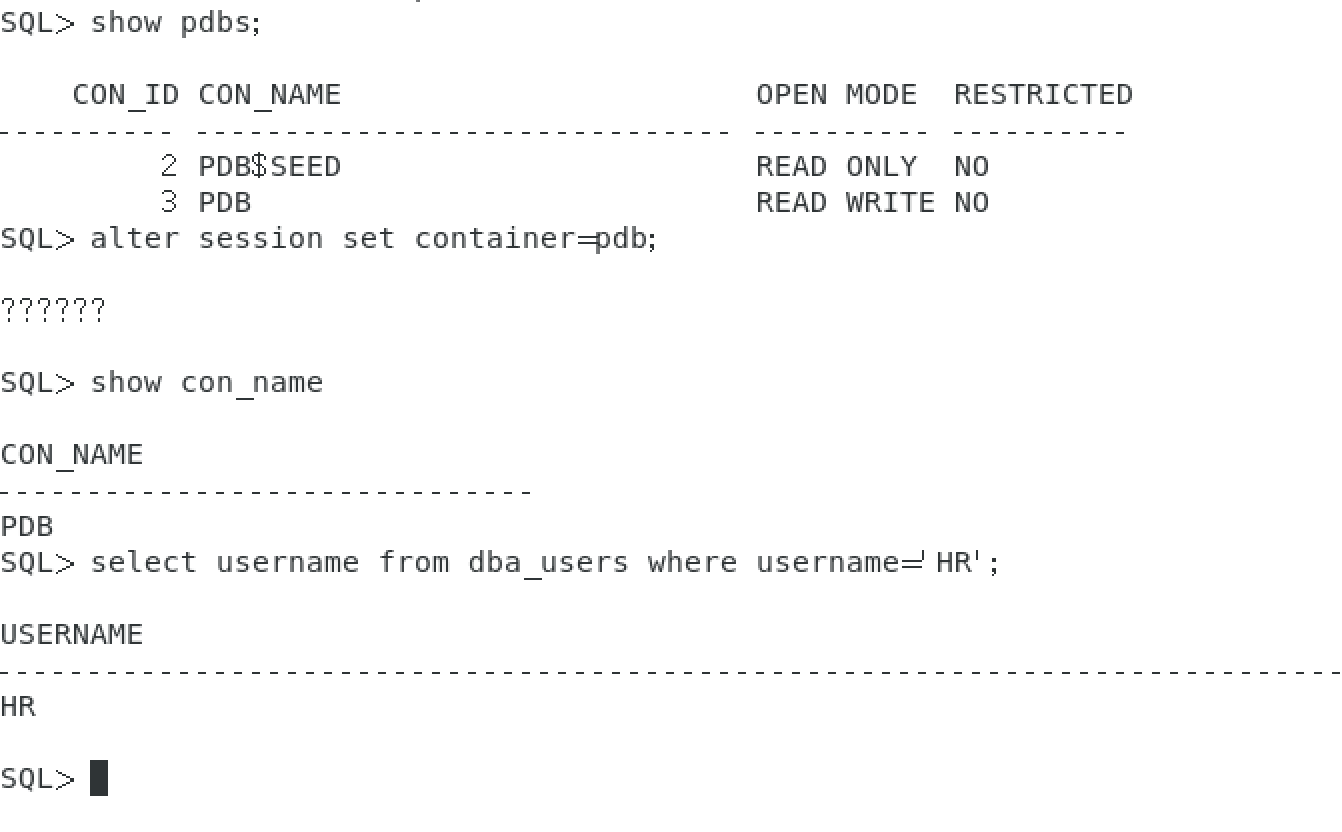
切换到容器数据库,查看示例数据库
SQL优化
SQL执行顺序
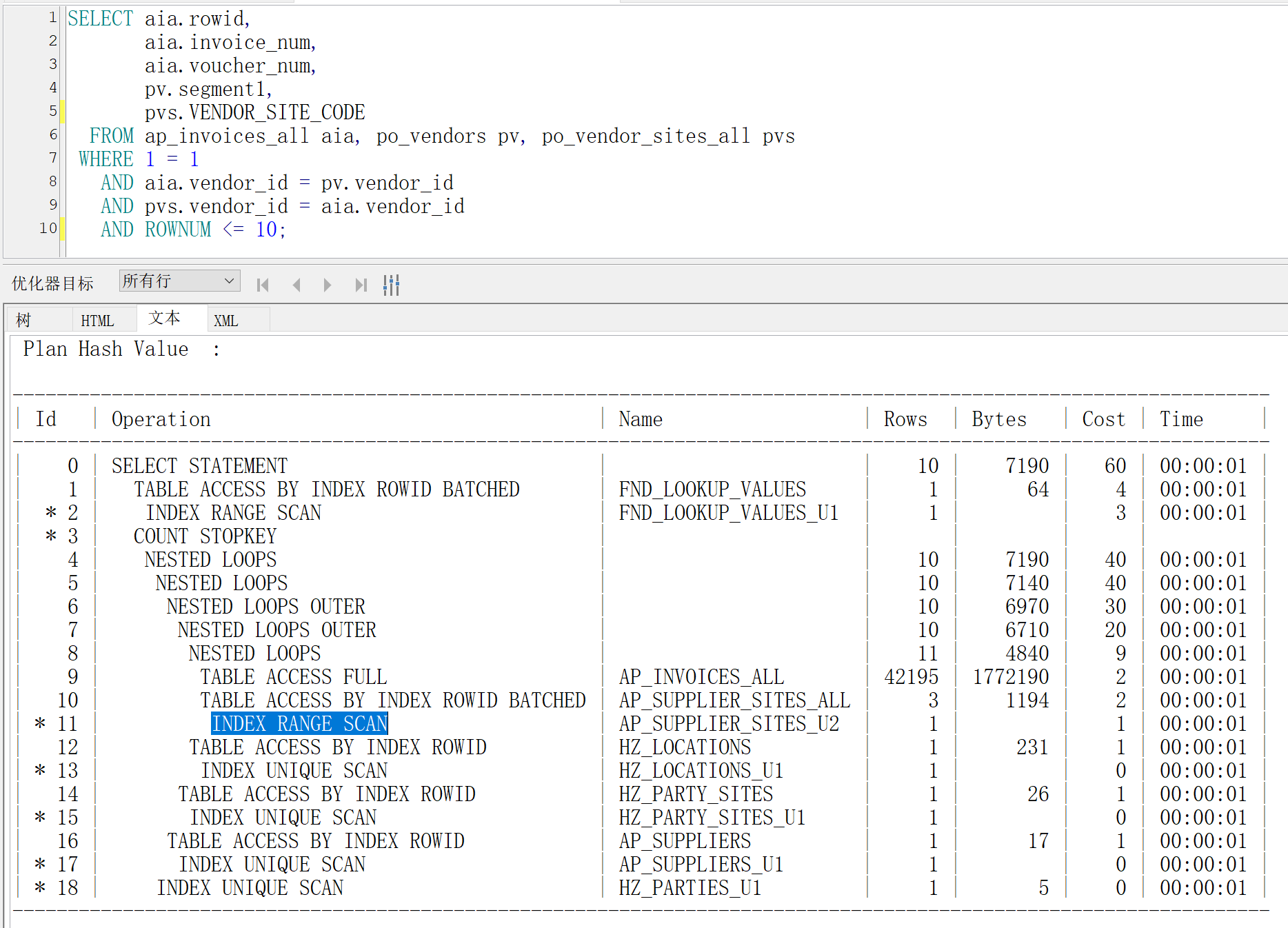
示例sql
1 | SELECT |
from -> where -> select -> order by
从结果集中筛选结果,并选取结果列,最后排序
SQL解释计划
概念
读取原则:从上往下读,从里往外读,靠上边的和靠里边的先执行
- rowid:oracle生成的物理地址
- FULL SCAN:全扫描
- UNIQUE SCAN:索引扫描(索引都是有序存放,需要消耗存储空间,保存的是不同的rowid)
示例
【注意】从sql developer上看可能显示会好一些
sql developer的解释计划示例
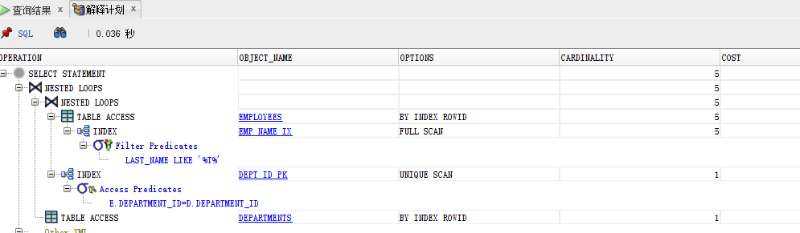
plsql developer的解释计划示例
Rows:解释计划结果集预估行数
Cost:解释计划步骤的系统开销
ORACLE多表关联查询的方式
- NESTED LOOPS :嵌套循环连接,CBO下的优化器,oracle会自动评估外层循环的基表,即自动评估左连接的基表
- HASH JOIN:为id生成hash值,把hash值相同的数据关联(10g以后),适合大表之间的连接
- Sorted Merge:排序后两表合并
STEP1 保证信息一致
要确保解释计划出来的数据,与数据库中实际的数据一致。
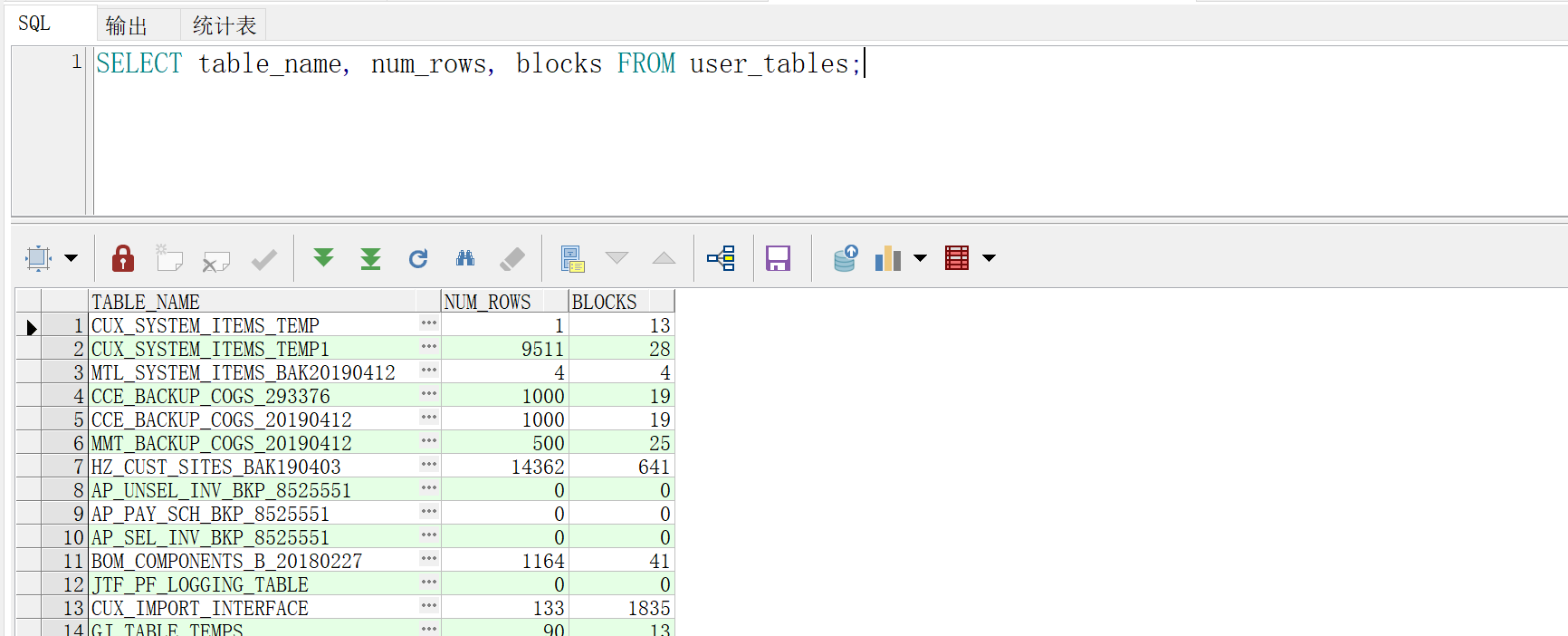
查看表的统计信息
SELECT table_name, num_rows, blocks FROM user_tables;
oracle每日晚上22:00 - 凌晨2:00自动收集,oracle的执行计划会根据收集的统计信息来评估解释计划。
对于新建的数据表,由于没有收集统计信息,在解释计划中的 Rows 可能跟实际新建的表不符合,此时要主动收集一下数据库的信息。
【注意】统计信息的收集尽量不要与业务时间冲突,非常消耗性能。
收集统计信息
exec dbms_stats.gather_table_status(‘HR’,’Employees’);
【注意】如果由于统计不准,导致选错执行计划,会导致查询变得非常缓慢。
【注意】12c以后:执行sql的时候有一次改变执行计划的可能性,可能会把嵌套循环连接变成 Hash Join。在执行前会扫描索引并收集一次信息,根据查询的结果和解释计划进行比较,如果差异较大则会改变执行计划。
STEP2 优化工具
概览
ORACLE STA优化脚本
- 语句改写
- 收集表信息
- 修改执行计划
- 构建分区表
- 构建索引
- 构建物化视图
AWR报告
SQL Developer
ORACLE STA
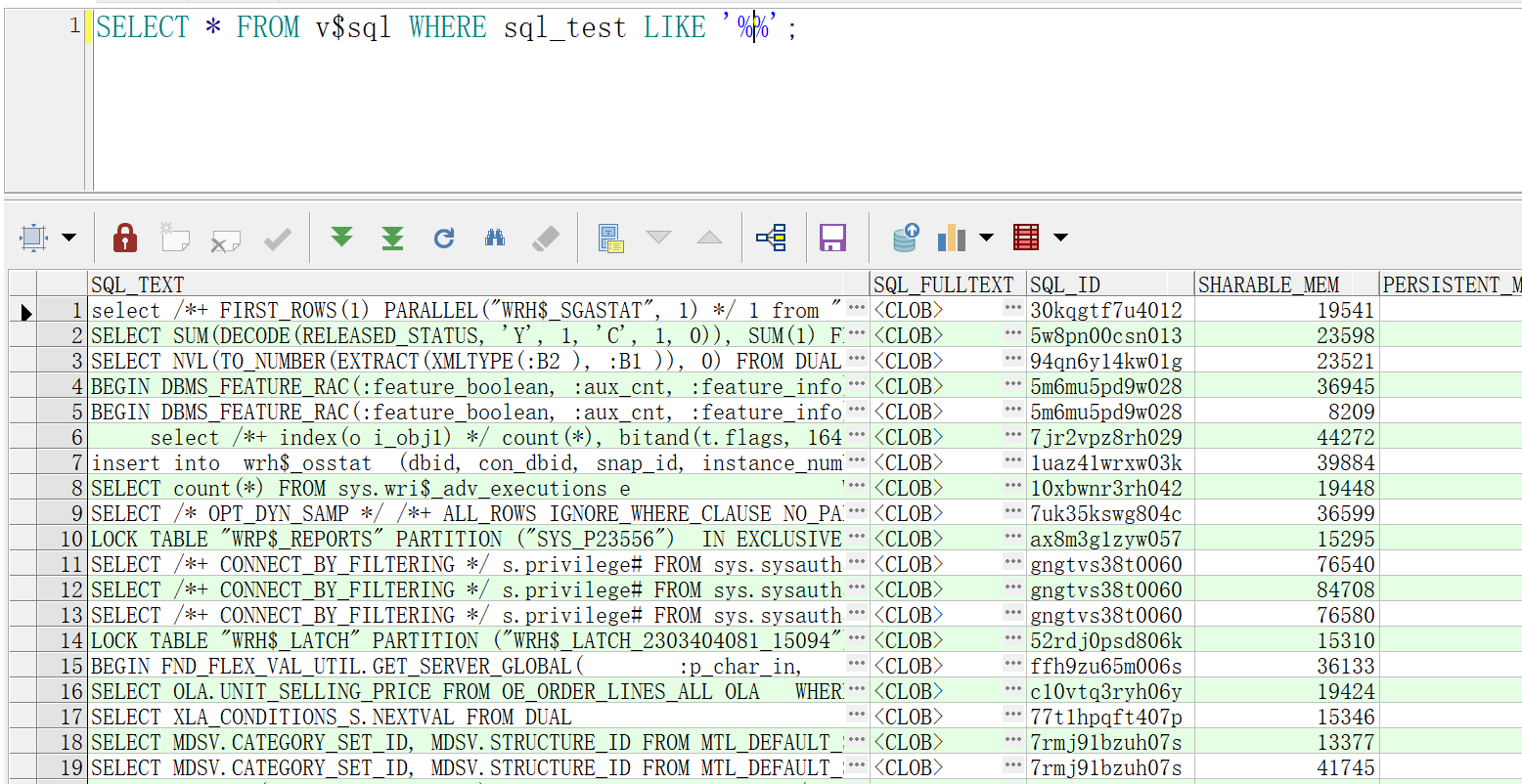
查找sql的id,该查询会从内存中获取近期执行的sql语句
SELECT * FROM v$sql WHERE sql_test LIKE ‘%%’;
结果如下:
使用STA工具优化
@?/rdbms/admin/sqltrpt.sql
结果如下,会显示近期15条最消耗性能的sql
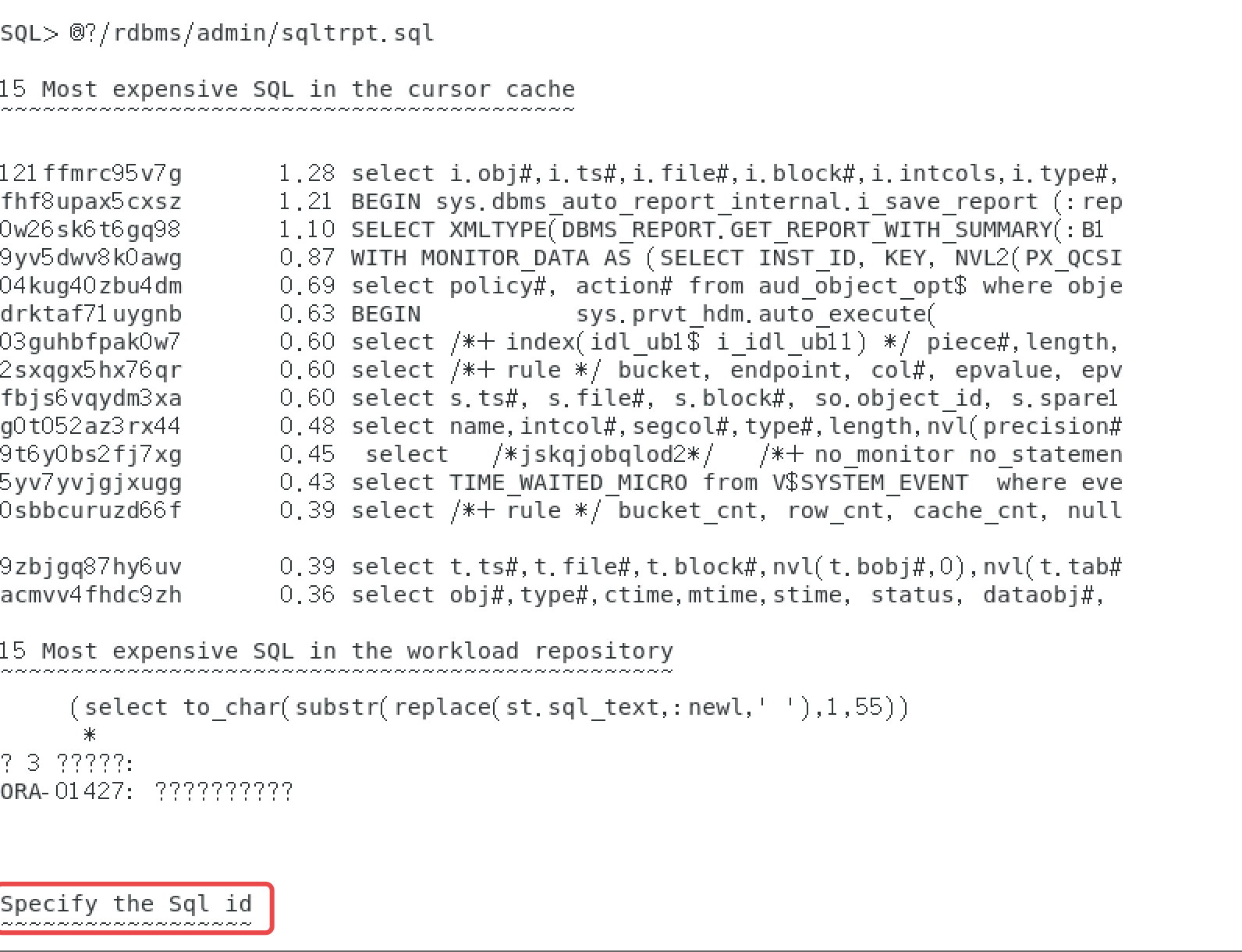
此时输入sql的id,则可以生成优化建议,并且可以看到改正后的执行计划
#TODO# 建议实际操作一下
SQL Developer
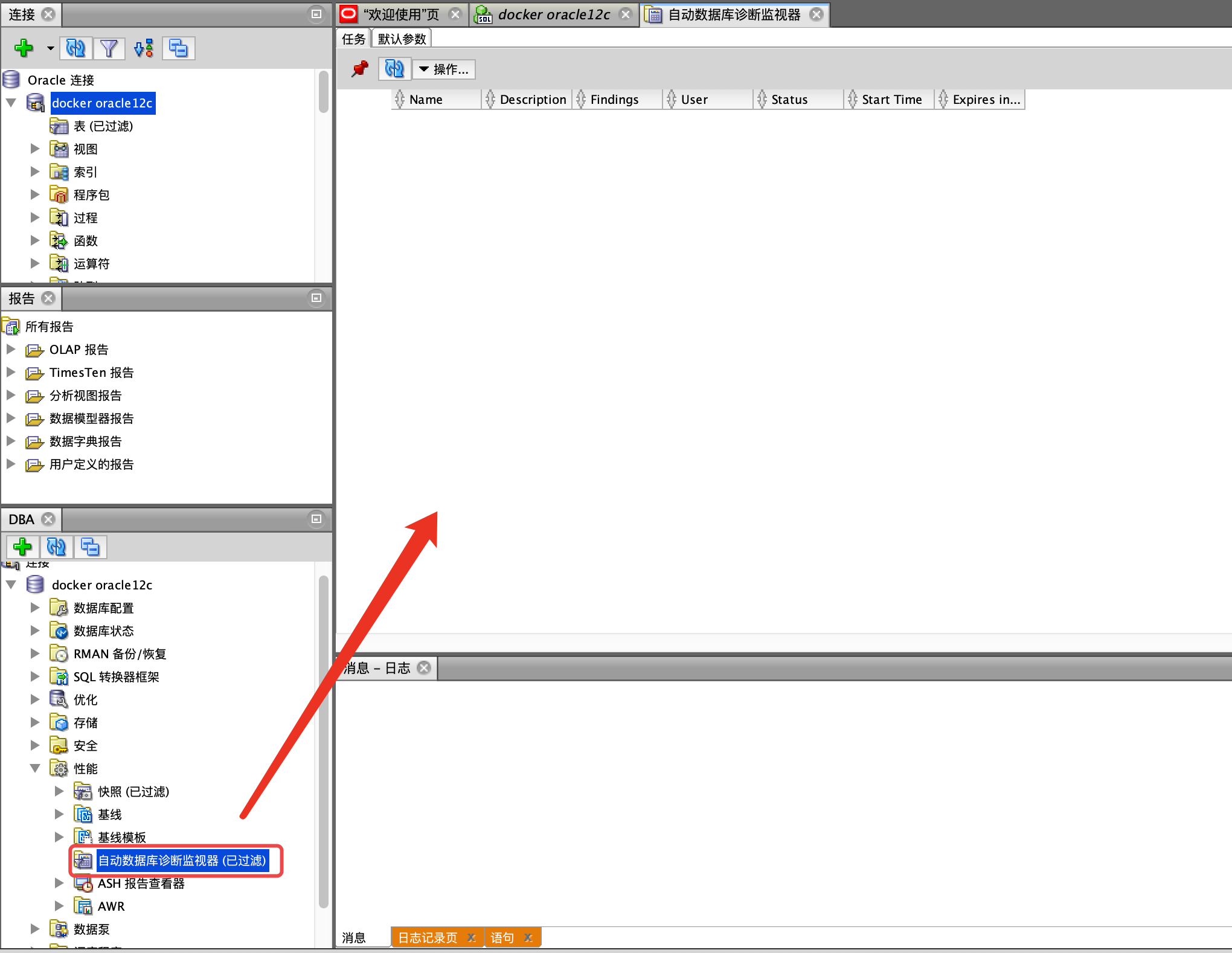
1.自动诊断
路径:查看 -> DBA -> 性能 -> 自动数据库诊断监视器
每小时会自动生成性能诊断报告
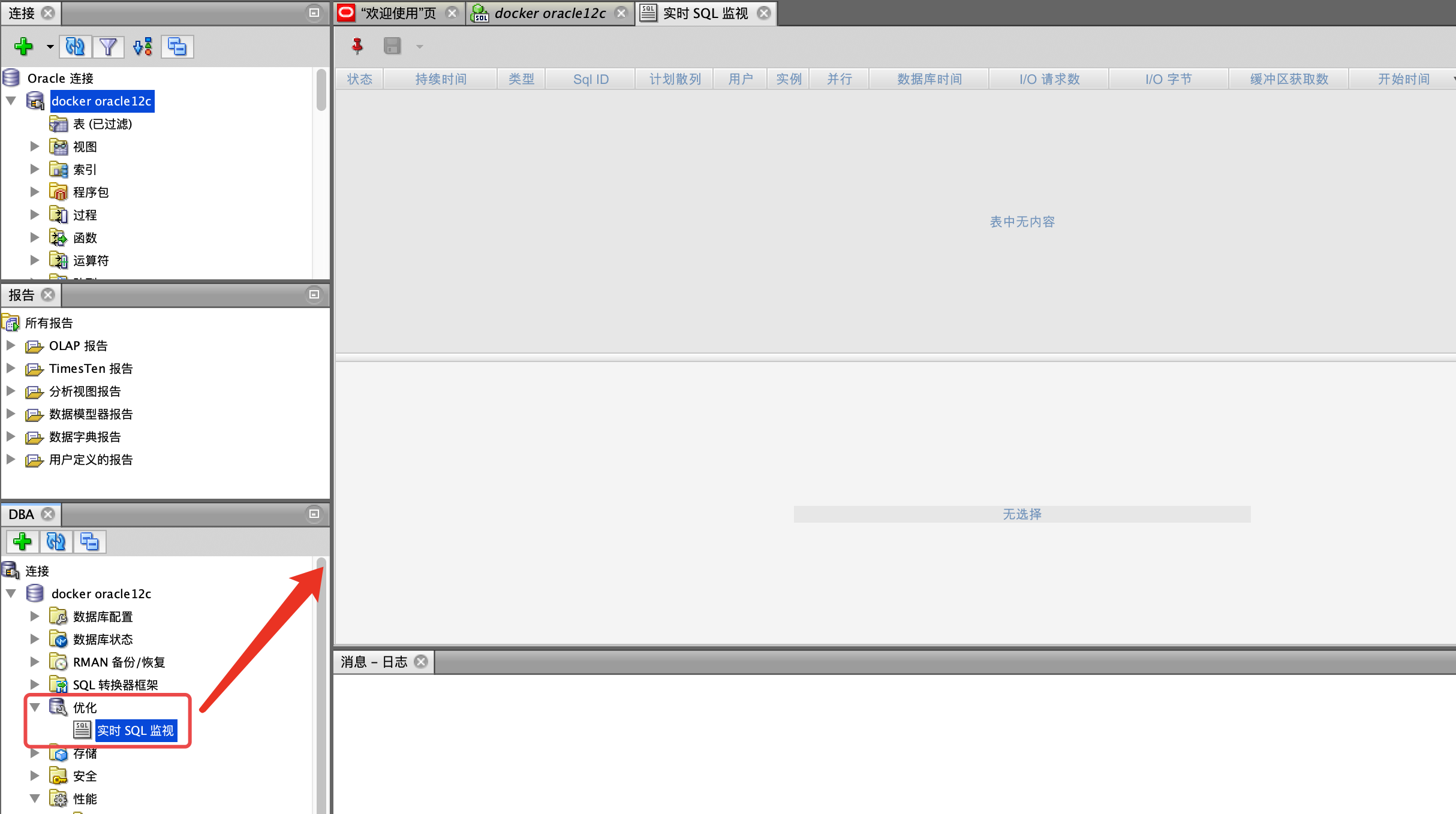
2.实时监控
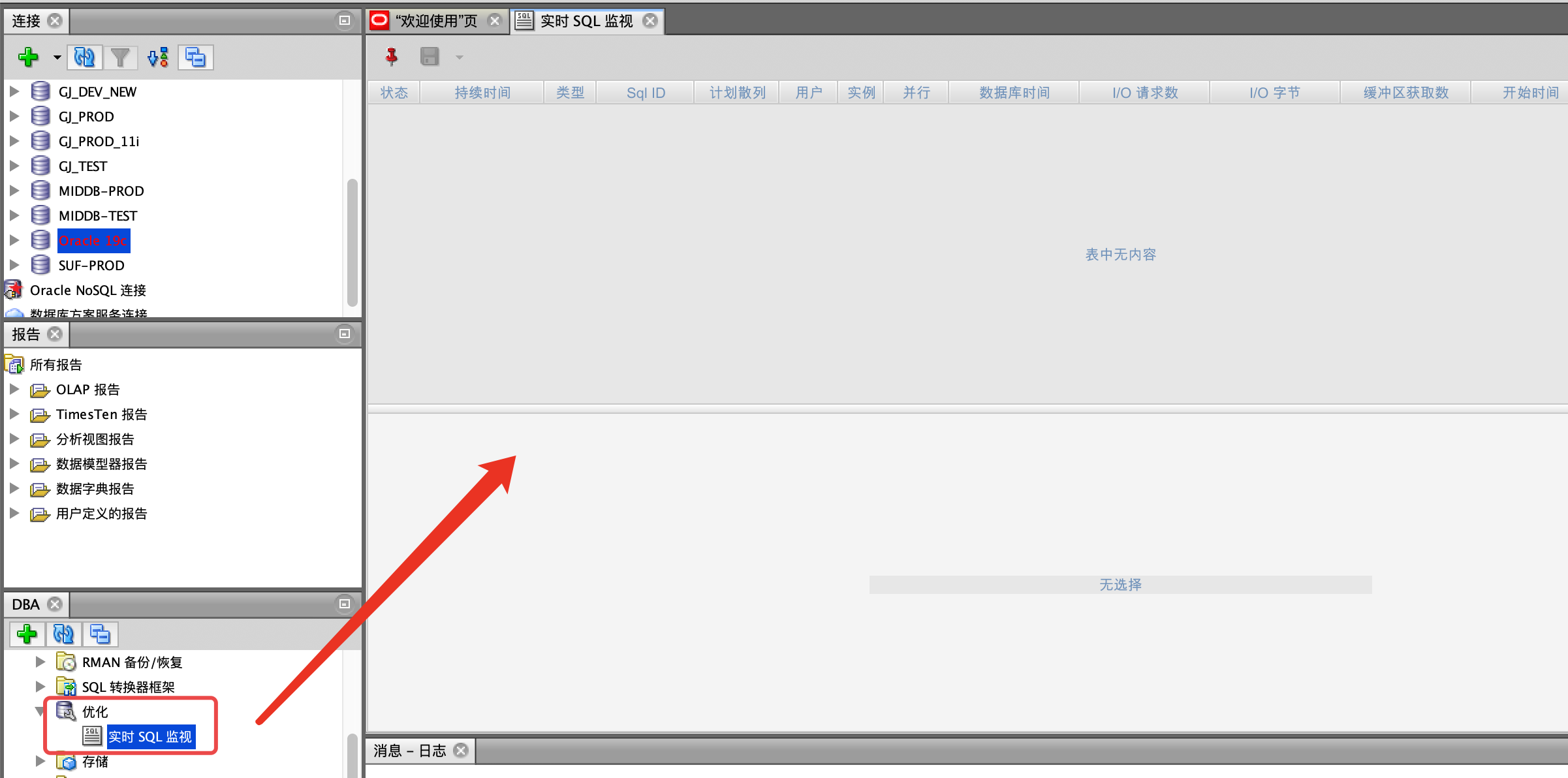
路径:查看 -> DBA -> 优化 -> 实时SQL监视
AWR报告部分
找到 ADDM Reports
Cloud Control
Oracle Enterprise Manager Cloud Control
可视化的oracle数据库管理系统,见虚拟机2
Oracle性能分析
AWR报告
通过SQL Developer可视化生成报告;抑或是采用命令方式生成。
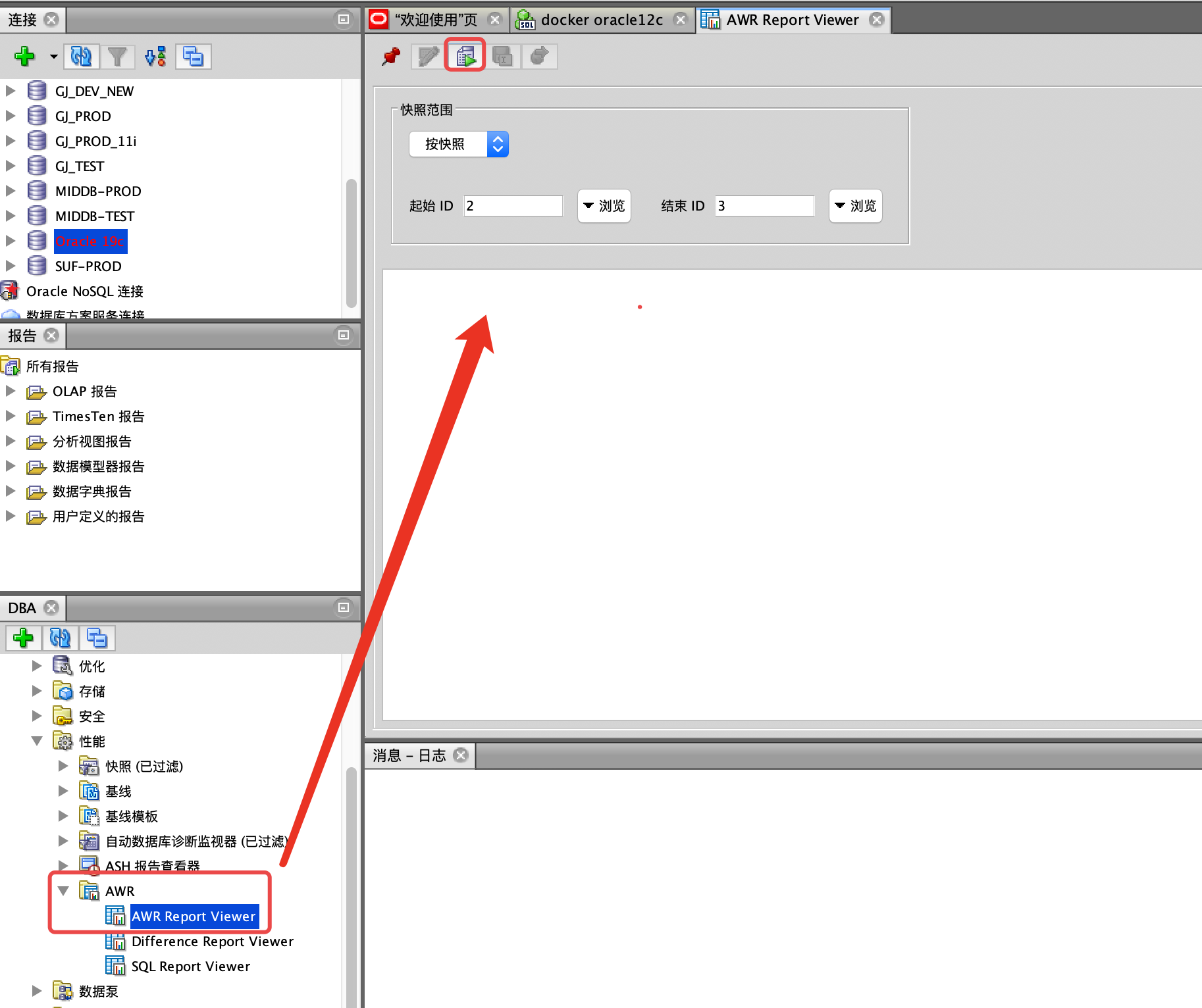
命令方式
@?/rdbms/admin/awrrpt.sql
简单的性能分析
Report Summary
- 确定系统类型:分析/交易 类型
- Redo Size (Per Second):Redo量小,可能是分析类型的系统;如果大的话可能是交易类型的系统
- Logical read(从内存里取数称为逻辑度):如果量大,则可能为大量的select查询
- Transactions:每秒事务数
SQL ordered by Elapsed Time
- Elapsed Time:在报告生成时间内执行总时间,等于执行次数 * 每秒执行时间
- Executions:执行次数
- Elapsed Time per Exec(s):每秒执行时间
- SQL Id:SQL查询id,不同的库是一样的。生成方式:把SQL转换成ASCII码,然后针对ASCII码生成hash码。
SQL ordered by Gets
- 逻辑读
- Buffer Gets:逻辑读总时间
- Executions:执行次数
- Gets per Exec:单次逻辑读时间
SQL ordered by Reads
- 物理读
Top 5 Evnets
- 最消耗性能的5个事件
通过SQL Developer优化
查看实时SQL监视
路径:查看 -> DBA
查看SQL顶级报告
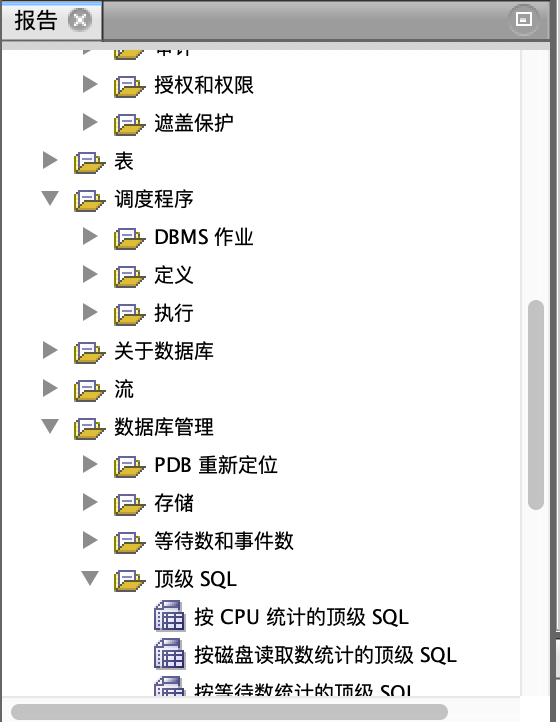
路径:查看 -> 报告 -> 数据字典报告 -> 数据库管理 -> 顶级SQL
SQL 优化手册
SQL Tuning Guide
Database Performance Tuning Guide
Shared Pool Check,即软解析,存放常用解析后的结果
Soft Parse,即软解析,如果软解析过大,可能会出现在
Shared Pool Check中出现资源争抢,超出资源限制的请求将进入队列等待。Hard Parse,即硬解析,语句首次执行,消耗CPU
- OLAP(分析类型事务),实现硬解析,不要有软解析
- OLTP(处理类型事务),尽可能多地实现软解析
- 尽可能在写SQL的时候,保证大小写,因为SQL语句是通过ASCII码生成hashCode来判断是否实现软解析,而大小写的ASCII码不同,会导致硬解析。
Optimization,即优化器,当sql进入硬解析的时候,优化器会判断是走索引还是全表扫描。
RBO,即rule-based optimizer,指基于规则的优化
CBO,即cost-based optimizer,指基于开销的优化,需要考虑诸多因素的成本,给出最符合条件的sql结果(10g以后,CBO为默认优化模式)
- CPU
- IO
- 内存
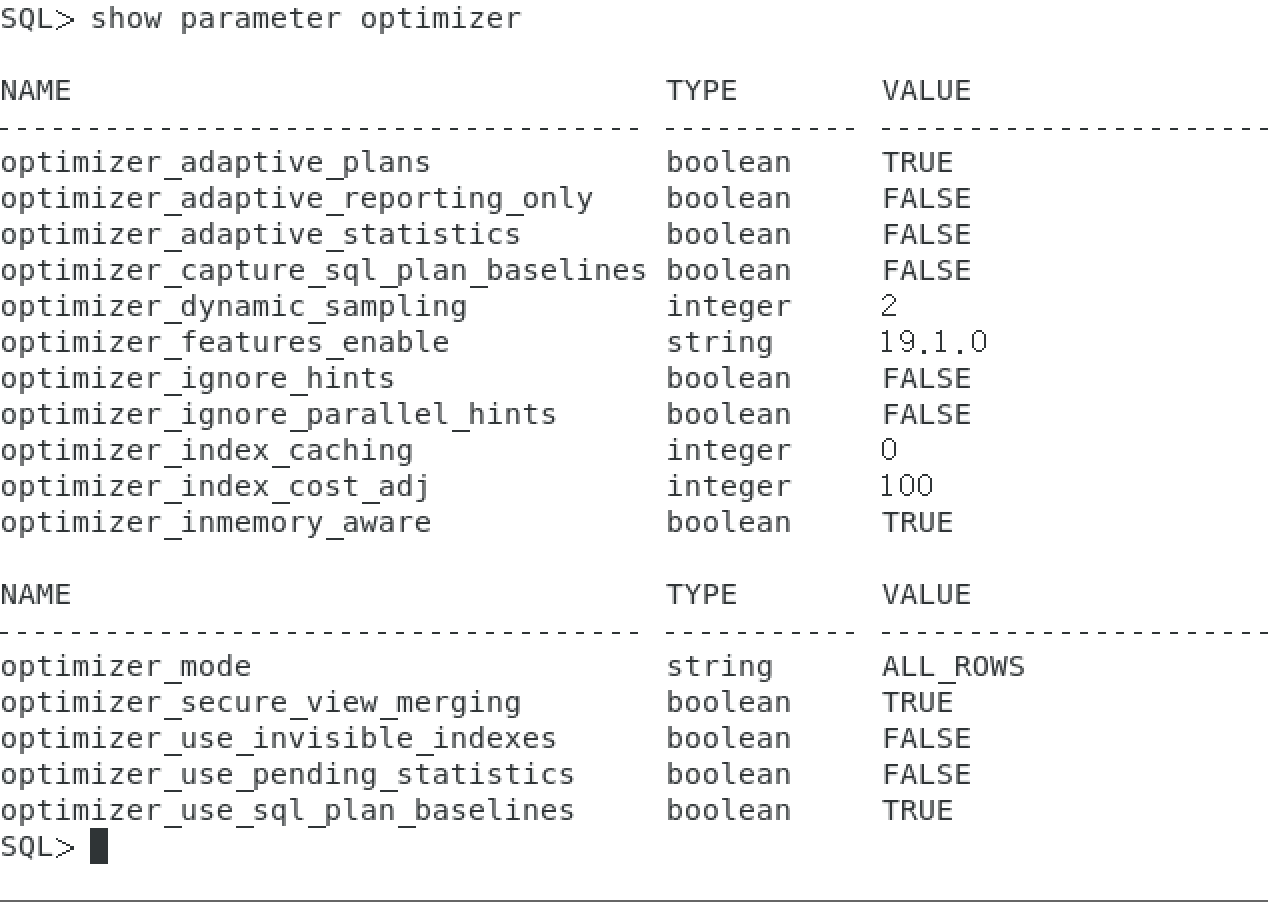
查看优化器
show parameter optimizer
修改优化器模式
alter system set optimizer_mode = ‘rule’
软解析与硬解析实例
实例1:
select count(*) from test1; –硬解析
select count(*) from TEST1; –修改表名再次执行,也是硬解析
实例2:
使用绑定变量,则多次执行也会被判断为软解析
select count(*) from TEST1 where id= :x ; –使用绑定变量
实例3:
分析型系统,少有软解析。如果是分析型数据检索大量数据,尽量全表扫描,不要走索引;如果是检索少量数据,走索引速度会更快。
分析类型的数据是倾斜的,查找的数据是不定的,不均匀的。如果采用绑定变量的方式,实现软解析,那么面对倾斜数据时,根据软解析复用执行计划,针对应该走索引和全表扫描的查询,都执行同样的执行计划显然是不合理的。
降低分析型系统(如数据仓库等)响应时间的方法:
使物理读变为逻辑读
使用更好的压缩技术
使用更好的并行查询技术,使用大量的进程并行查询
更换硬盘,提高IO速度
更好的扫描算法
Oracle In-Memory Database内存数据库会自动删除索引,更适合于分析类型。
#TODO# 实践的方法?如:AWR报告分析、SQL优化技巧实战