函数式编程学习总结
为什么需要函数式编程
java的抽象级别不够,在处理大型数据集合的时候,java欠缺高效的并行操作。
OOP(Object Oriented Programming,面向对象编程)是对数据进行抽象,而FP(Functional Programming,函数式编程)是对行为进行抽象。
在现实世界中,数据和行为并存,程序也是如此,因此两种编程方式都要学习。
函数式编程这种新的抽象方式还有其他好处:程序员能够编写出更容易阅读的代码——这种代码更多的表达了业务逻辑的意图,而不是它的实现机制。
Lambda表达式
形如:
- () -> {实现逻辑};
lambda表达式实例
1 |
|
方法引用(Function Reference)
语法为:Classname::methodName ,其中 :: 操作符被称为方法引用操作符。
凡是能够使用lambda标准表达式x -> x.method()的情况下,都能够使用方法引用。
1 | public static void main(String[] args) { |
重要的函数接口
函数式编程最重要的是 方法签名 ,它声明了函数的入参和出参,是函数式编程的基石。
- Predicate
- Consumer
- Function<T,R>
- Supplier
- UnaryOperator
- BinaryOperator
@FunctionalInterface
#TODO#
流
什么是流
流指随着时间产生的数据序列
java8 Stream:指为一组序列提供顺序、并行的计算
- 支持函数式编程
- 提供管道运算能力
- 提供并发并行(parallel)计算能力
- 提供大量操作
Stream是用函数式编程方式在集合上进行复杂操作的工具
惰性求值
惰性求值(lazy evaluation):最终不产生新集合(或新返回值),指描述Stream的方法,叫惰性求值方法。
实例:
1 | public static void main(String[] args) { |
及早求值:最终会从Stream产生值的方法,叫做及早求值。
这种最终产生值的方法,称为终结操作/方法
1 | public static void main(String[] args) { |
判断方法:
如果返回值是Stream(Pipe Line),则是惰性求值;如果返回值是另一个值或者空,则为及早求值。
整个过程和
建造者模式有共通之处。建造者模式使用一系列操作设置属性和配置,最后用一个 build 方法,这时对象才被真正创建。
of 与 Optional
在面向对象的编程中,对象是一等公民,一般通过 new 关键字来创建对象,基本类型也都有对应的包装类。
在函数式编程中,函数是一等公民,需要一个专属的返回值和创建流的方法。
of 用于构造自己的流,是流的
工厂方法Optional 是流中专属的返回值,用来替换
null值- 把Stream中的返回值进行装箱,防止各种异常的产生,使流计算更加安全
1 |
|
【注意】可以通过 orElse 方法,避免返回 Optional
常用的流操作
【注意】以下例子均为最简单实例,均可以在方法中调用自定义的函数。
collect
collect方法有stream里的值生成一个列表,是一个及早求值操作。
1 | public static void main(String[] args) { |
map
如果有一个函数可以将一种类型的值转换为另一种类型,map操作就可以使用该函数,将一个流中的值转换成一个新的流。
1 | public static void main(String[] args) { |
filter
遍历数据并检查/过滤其中元素时,可以尝试使用该方法。见 collect 中的例子组合使用
flatmap
flatmap方法可以用stream替换值,然后将多个stream连接成一个。
1 |
|
max & min
求最值
1 |
|
reduce
该方法可以从一组值中生成一个值,如累加等
1 |
|
sorted
使用sorted方法能够使流中的数据按从小到大的顺序排列;
1 | public static void main(String[] args) { |
unordered
有一些流的操作会使数据自动排序。一些操作在有序的流上开销会更大,而使用该方法能消除这种自动排序的操作。
【注意】以下实例中的map并不会引起数据的自动排序,实例并不是十分准确。
1 | public static void main(String[] args) { |
partitioningBy
该方法用于将流分解为两个集合,一部分为符合条件的集合,另一部分为不符合条件的集合。
要注意的是partitioningBy里面的返回值必须为boolean类型
1 | public static void main(String[] args) { |
groupingBy
该方法用于将数据分割为多个list
该方法与SQL中的group by操作蕾丝,只是在Stream类库中将其实现了
1 |
|
并行处理
以并行计算为例
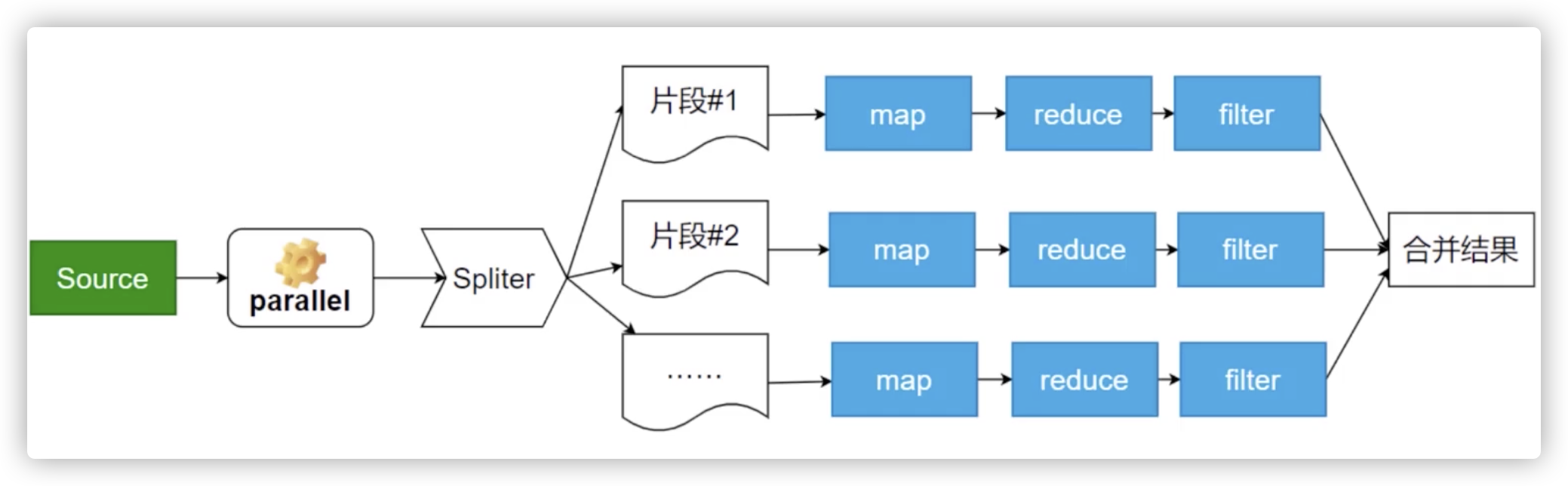
coding实例
1 | // 流并行计算实例 |
结果:
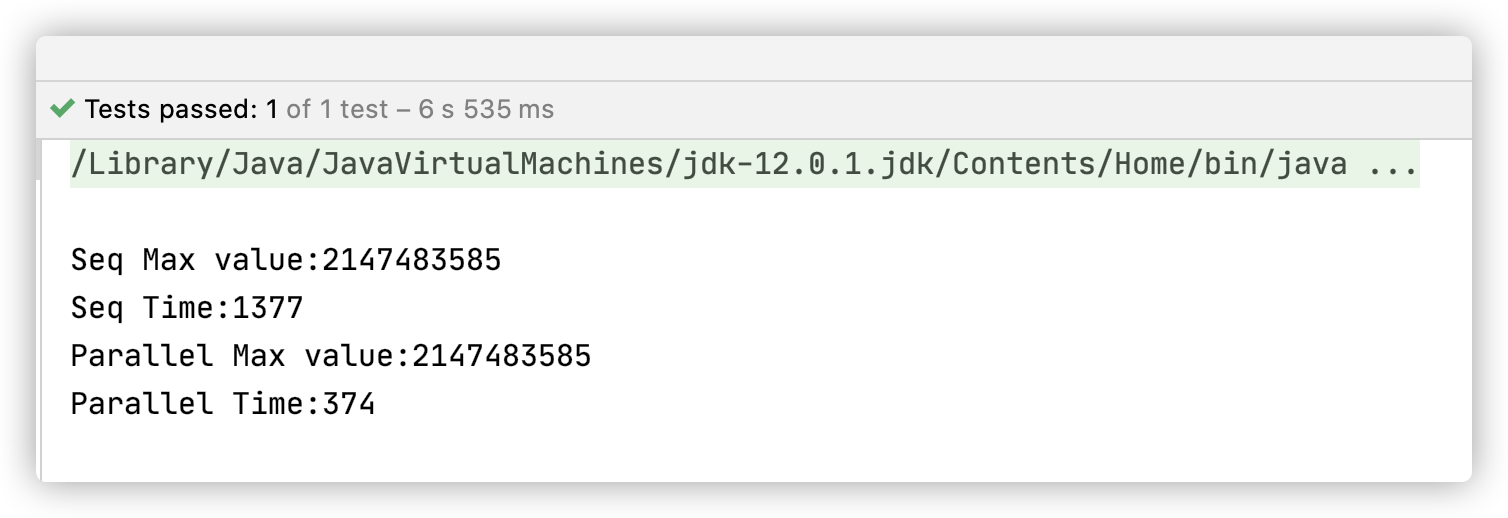
并行流性能的因素
1.性能指标
- 数据分块的大小:当数据足够大,每个数据处理管道花费的时间足够多时,并行化处理才有意义
- 装箱:处理基本类型比处理装箱类型要快,如果调用了
box方法,则会触发自动装箱,进而导致性能会下降 - cpu核数:拥有的可用核数越多,性能提升的幅度越大。可以通过方法
Runtime.getRuntime().availableProcessors()来获取可用核数 - 单元处理开销:花费在每个元素上的时间越长,并行操作带来的性能提升越明显
2.可以根据性能的好坏,将容器中的通用数据结构分成三组
性能好:ArrayList、数组
- 支持随机读取,可以很好地被分割
性能一般:HashSet、TreeSet
- 不易公平的被分解,但是大多数时候是可能的
性能差:LinkedList、Stream.lierate、BufferedReader.lines
- 长度未知、不支持随机读取、难以预测分割的位置
3.如果能避开有状态的操作,选用无状态的操作,能够获得更好的性能
无状态操作(stateless)
- filter
- flatmap
- map
有状态操作(stateful)
- sorted
- distinct
- limit
- skip
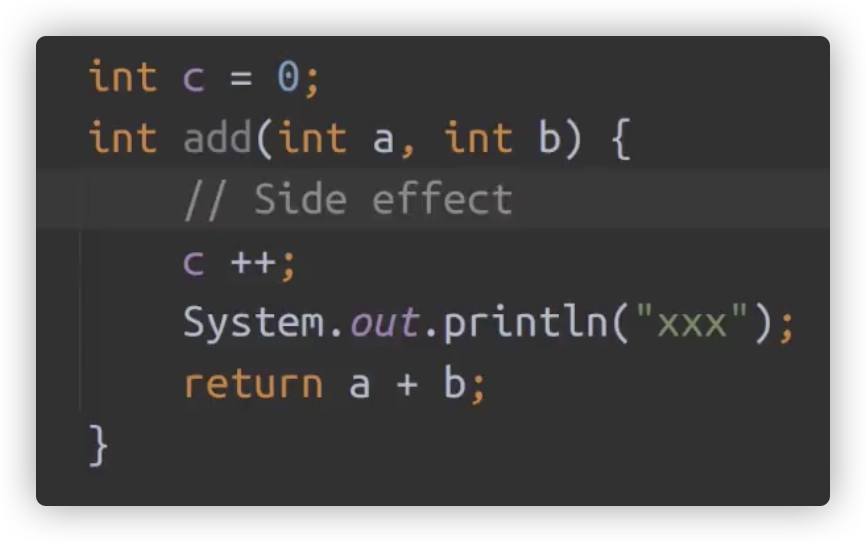
4.在函数式编程的时候,多使用纯函数(pure function)
纯函数指无副作用的函数,即纯计算的但一操作,不涉及其他操作的函数
非纯函数实例
5.函数式编程性质总结
- 一般使用纯函数(pure function),要求输入的数据不可变(immutable),仅仅对输入的数据做拷贝
- 惰性求值(lazy)
- 安全(Monad - safety)
这里的c属于外部变量,但是却在函数内部发生了计算,同时调用了I/O的操作,一旦发生异常,需要同时排查变量ab、变量c、IO设备。
串行处理
强制流串行处理
1 | public static void main(String[] args) { |
当 sequential 方法和 parallel 方法同时使用时,只有一个会生效。以最后一个调用的方法为准。
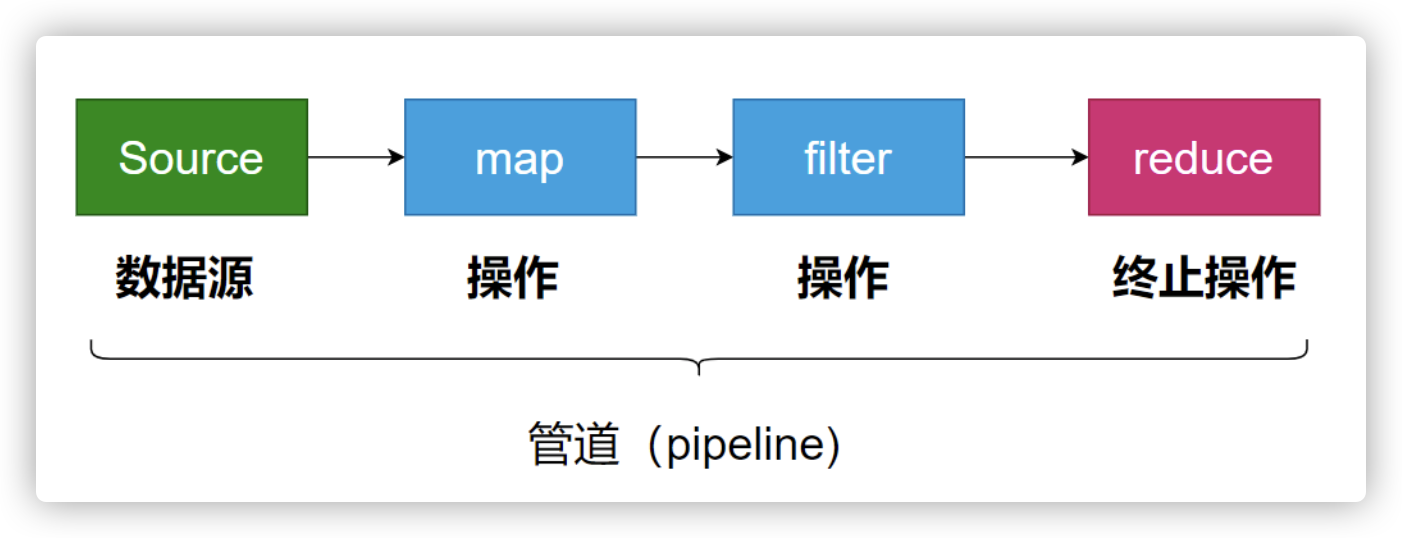
整合操作
map -> filter -> reduce
业务场景实例
实例一:
新旧写法的比较
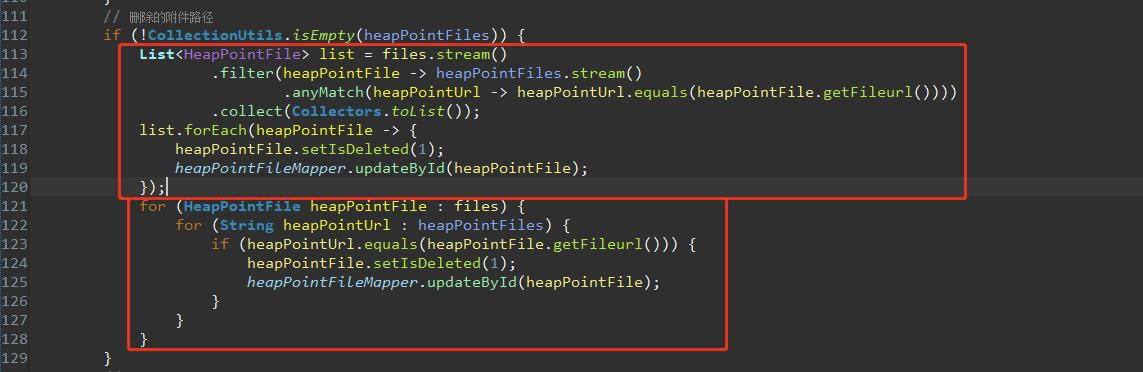
实例二:
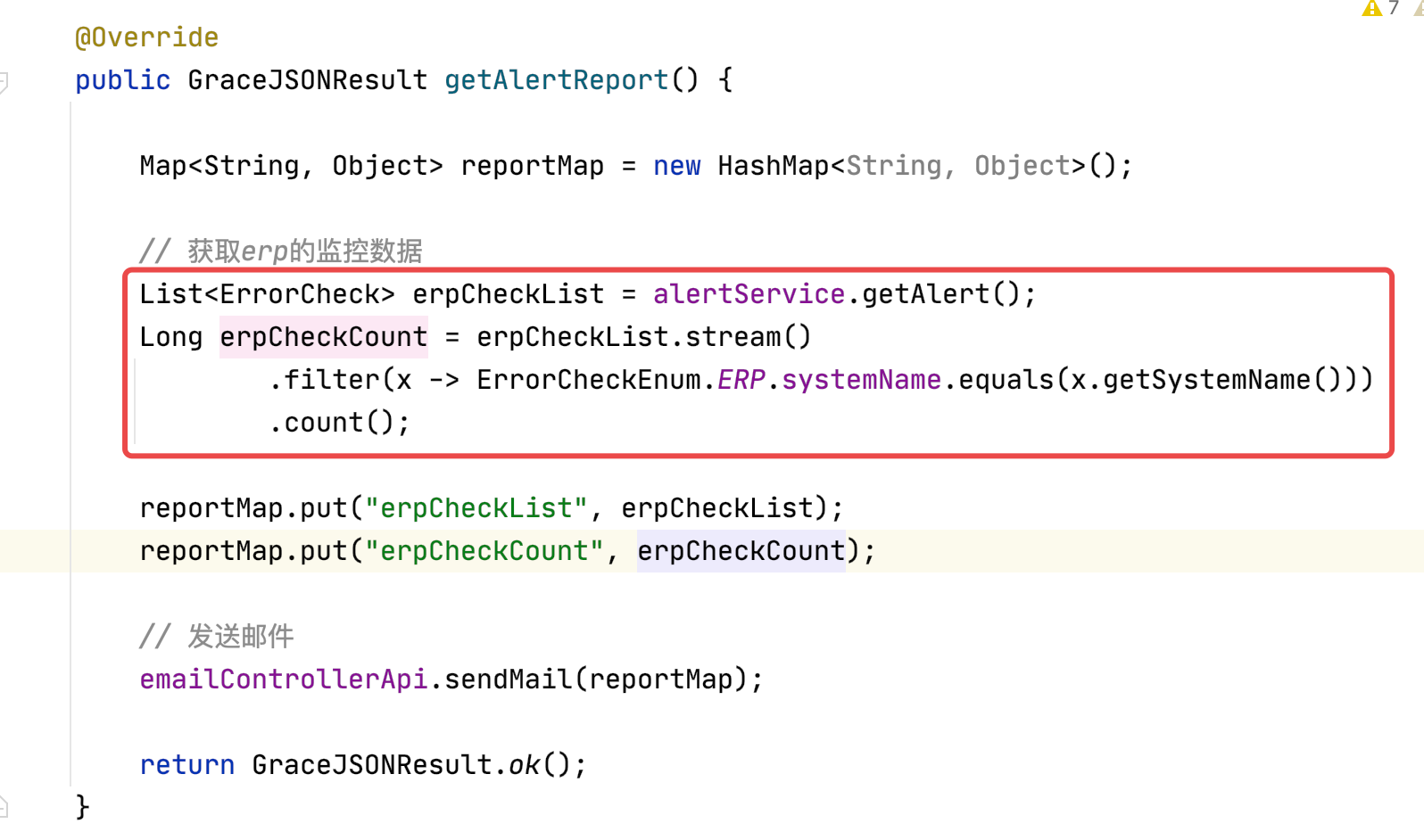
实例三:
并行计算最大值的区别
1 | var result = list.parallelStream().max((a, b) -> a - b).orElse(0); |
区别:
parallel()是把一个Stream变成parallelStream
parallelStream是把一个非stream(如 List)变成 parallelStream
Stream还是ParallelStream的max方法都是用reduce实现。
parallelStream的reduce方法有3个参数:(identity, accumulator, combiner)
- identity 初始值
- accumulator 单个线程如何累计,max就是一直算最大值
- combiner就是如何合并多个线程计算的结果s
参考书籍
《Java8 函数式编程》
《函数式编程思想》