*使用DeepSeek API测试
Function Calling
让AI调用已经定义好的python 方法
Function Calling 让模型能够调用外部工具,来增强自身能力。
- 将可以使用方法(工具)说明,随用户请求一起放在Prompt中传给GPT
- GPT返回要调用的方法及参数值,然后在外部运行该方法获得结果
- 将调用结果及前面的对话历史一起放入Prompt,再次调用GPT
例如:
- 构建一个dict对象存储:{“Method1”, “Method2”, …}
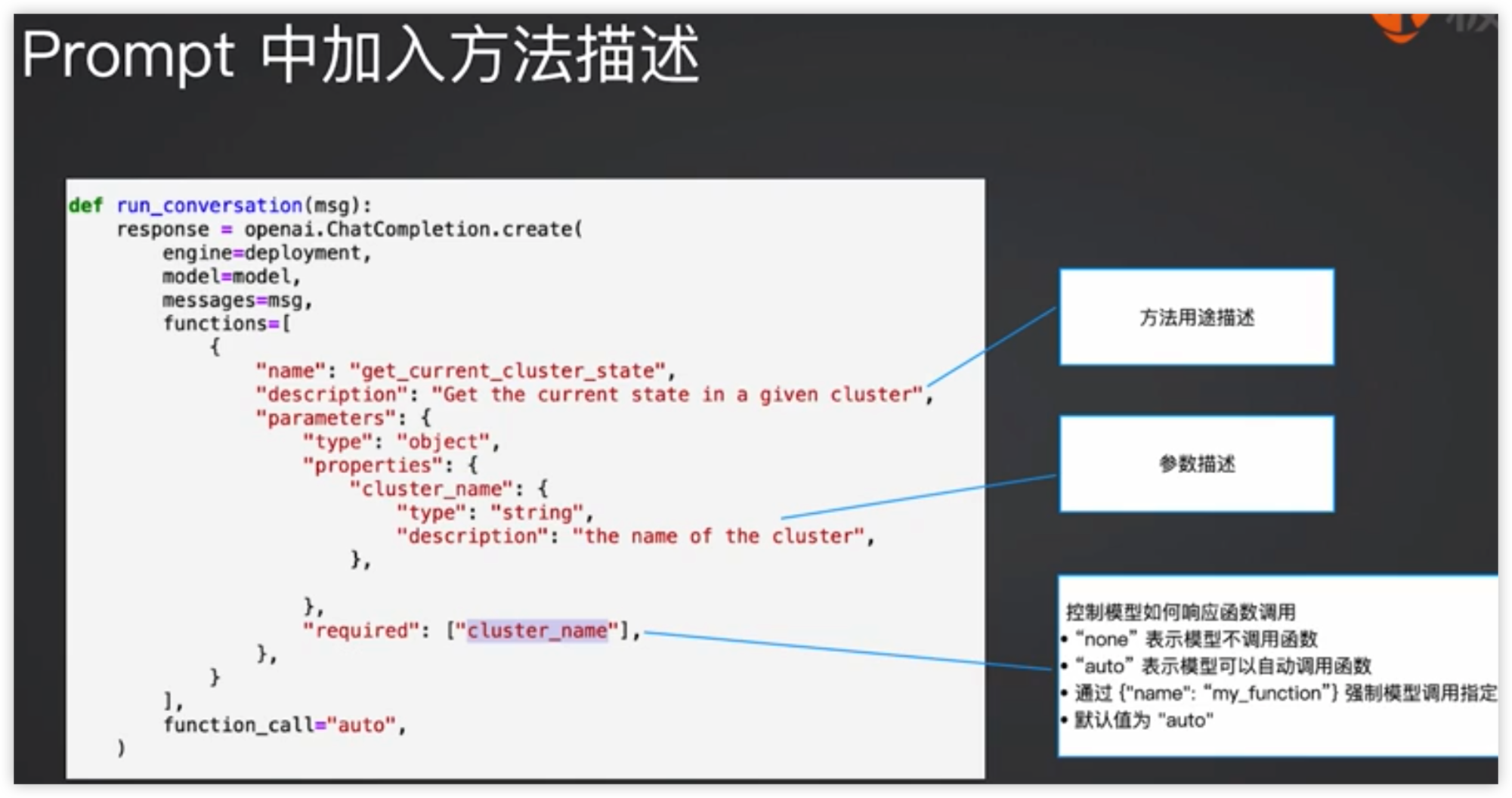
- 在Prompt中加入方法定义
- 根据LLM的返回,决定是否调用函数(返回信息中含有”Function_call”),还是直接返回信息给用户
- 如需调用函数,则调用LLM指定函数,并将结果及调用的函数一起放在Prompt中再次调用LLM
OpenAI GPT4o的例子
1 | import openai |
在Prompt中加入方法描述
DeepSeek示例源代码
目前会出现空回复的bug
https://github.com/KaloSora/HelloGPT/blob/dev/code/gpt_function_calling.ipynb
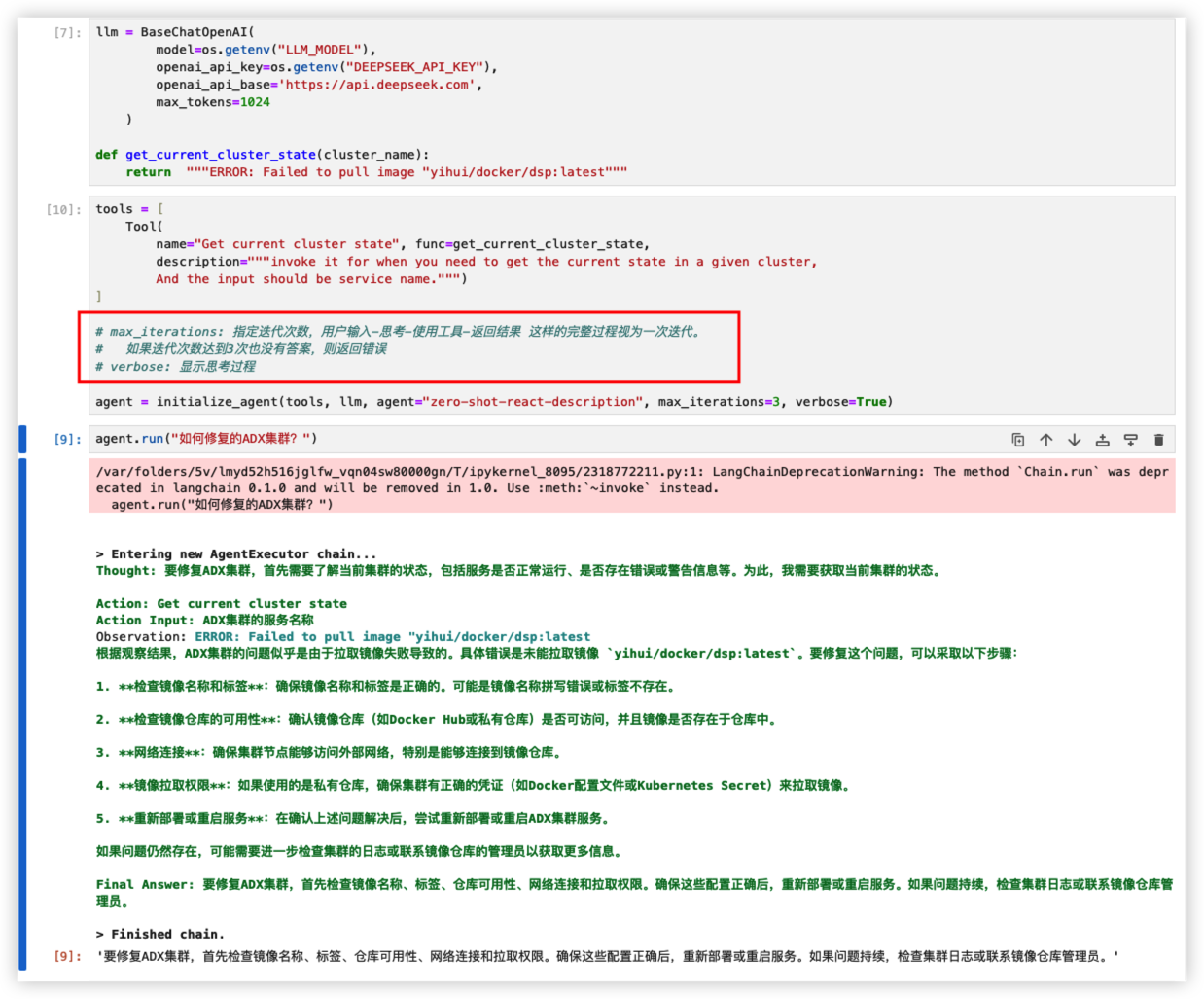
使用LangChain Agent
让GPT以更简单的方式,学会使用工具。
Agent的核心思想是使用语言模型来选择要采取的一系列操作。
LangChain 工具集
测试以后可以发现,LangChain使用工具的方法更加智能、灵活
Wolfram Alpha API Wrapper
Wolfram Alpha是专注于解决科学计算的工具,帮助AI更好得思考数学问题
官网
API ID Ceation
https://developer.wolframalpha.com
WolframAlphaAPIWrapper document
创建账号

创建你的APP ID
复制App ID
参考源代码
https://github.com/KaloSora/HelloGPT/blob/dev/code/gpt_langchain_agent.ipynb
In-context learning
Zero-shot Learning
一种机器学习方法,它允许模型在没有见过任何训练样本的情况下,对新类别的数据进行分类或识别。
这种方法通常依赖于模型在训练过程中学到的知识,以及对新类别的一些描述性信息,如属性或原数据。
例如,给出一些猫的特征,然后给出一堆图片,让机器识别出其中哪些图片是与猫相关的。
Few-shot Learning
教导模型使用非常有限的训练数据来识别新的对象、类或任务。在这里是通过Prompt里加入少量示例,来实现模型学习。
应用大语言模型要从传统机器学习思维切换为上下文学习思路
上下文学习包括Zero-shot Learning 和 Few-shot Learning,两者并无明显界限,可以根据实际需要灵活运用。
源代码
https://github.com/KaloSora/HelloGPT/blob/dev/code/gpt_in-ontext_learning.ipynb
ReAct模式
大语言模型具有推理能力,因为它们通过学习大量的文本数据,捕捉语言中的模式和结构。这些模型在训练过程中,会学习到各种知识、逻辑关系和推理方法。当它们遇到新的问题时,可以根据已经学到的知识和推理方法,生成有意义的回答。
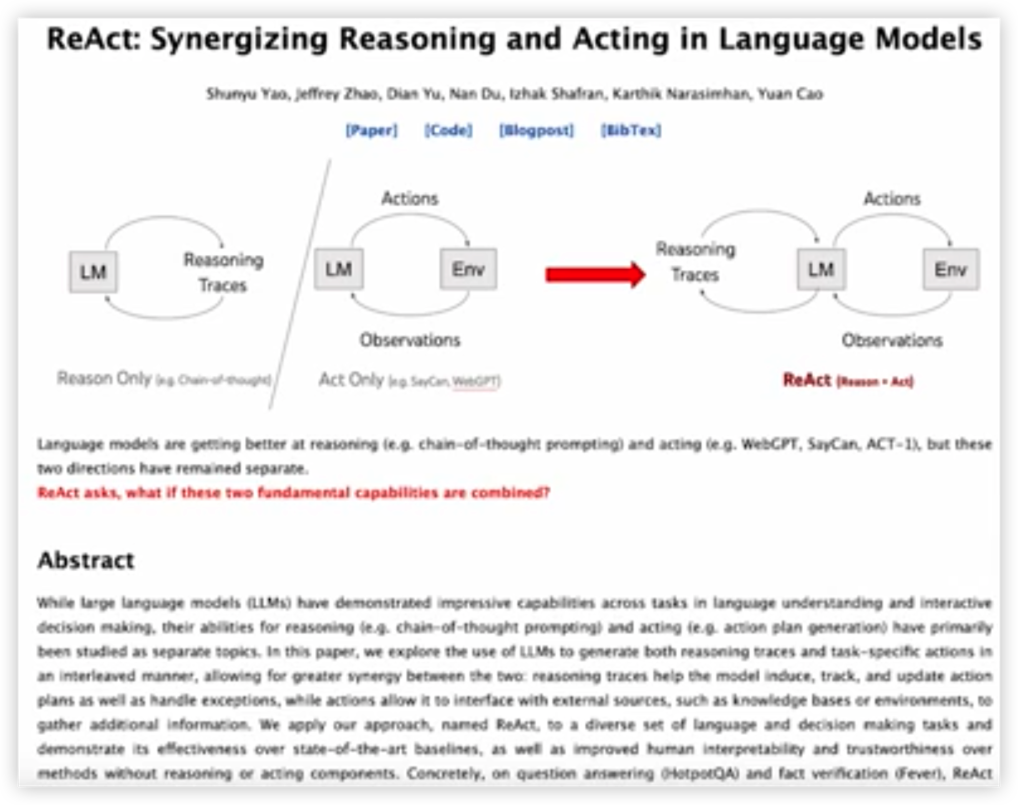
通过获取当前环境信息(观察),进一步思考,采取行动
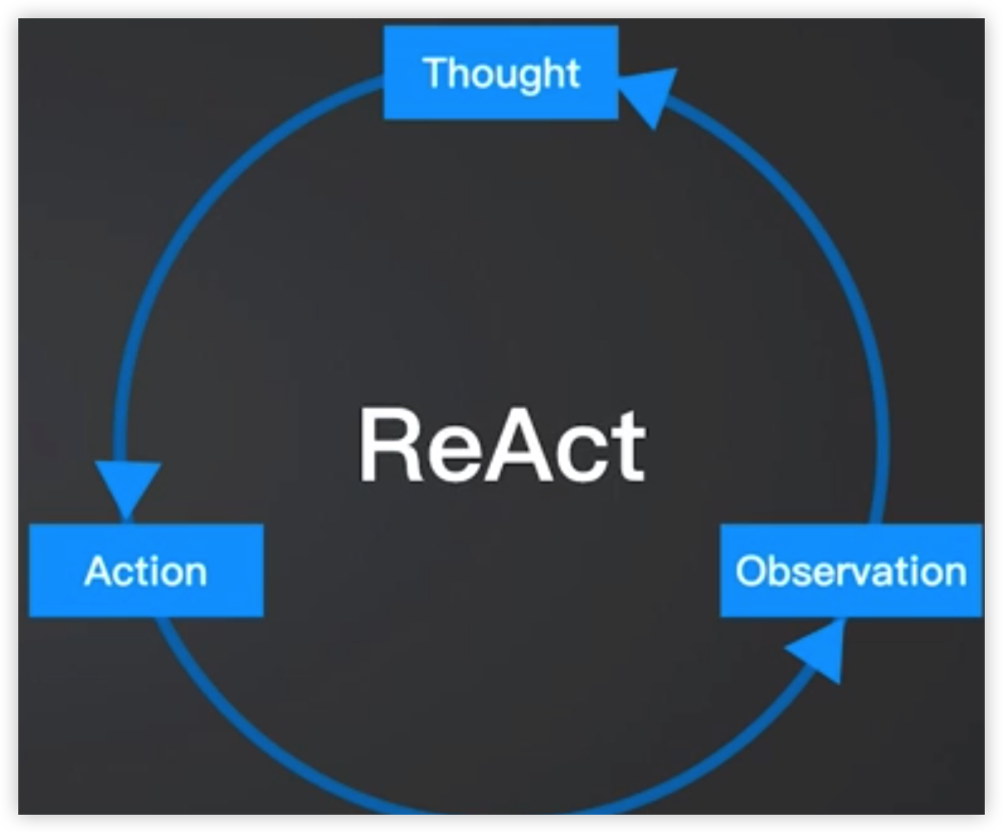
LangChain ReAct Agent

构建GPT,可以使用如下范式
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of thr action… (Though/Action/Action Input/Observation repeat N times)
Thought: Now I know the answer
Final Answer: the answer to the input question
AutoGPT - 针对某个解决方案的循环自执行GPT
如果可以,配合短期和长期记忆保证上下文效果。
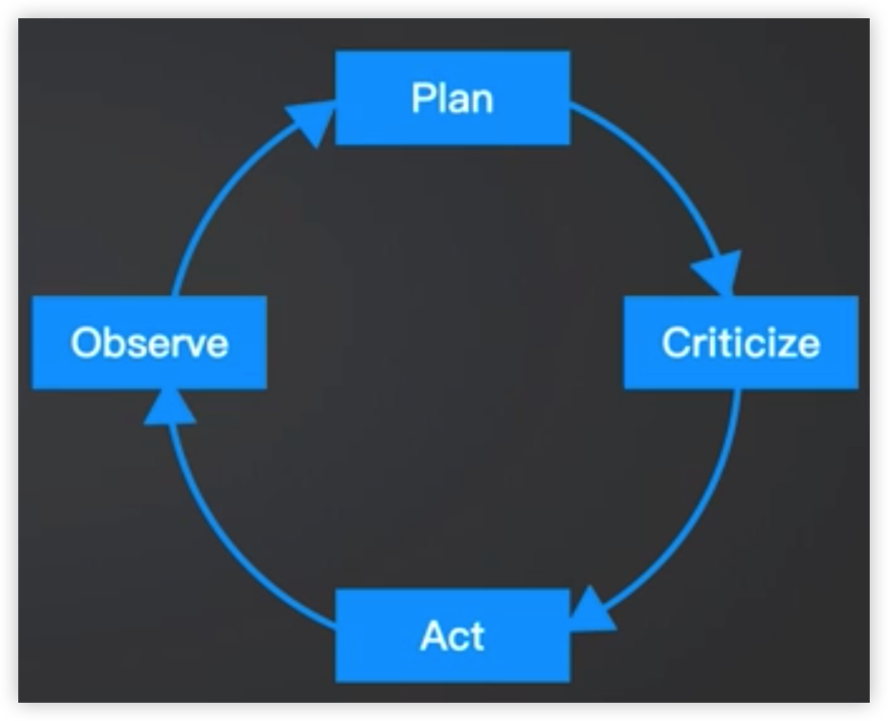
Plan: 设计实现预期结果的计划,将复杂的任务分解为较小的步骤。
Criticize: 评估计划的可行性和效率,识别潜在问题和改进领域
Act: 使用其多功能的能力执行计划的操作,例如网络搜索和数据检索
Observe:分析从Act中生成的反馈,从以前的性能中学习以改善未来的结果
Plan(修改):根据反馈,修改初始计划,允许持续改进问题解决策略
源代码
https://github.com/KaloSora/HelloGPT/blob/dev/code/gpt_autogpt_example.ipynb
文本分片与向量化
让大模型应用企业内部数据
大量文档和数据的挑战:如果使用prompt的方式来传递数据或上下文,会面临以下挑战:
- Prompt的内容大小限制
- 使用大量数据的成本
- 并非所有数据都会用于解决当前问题
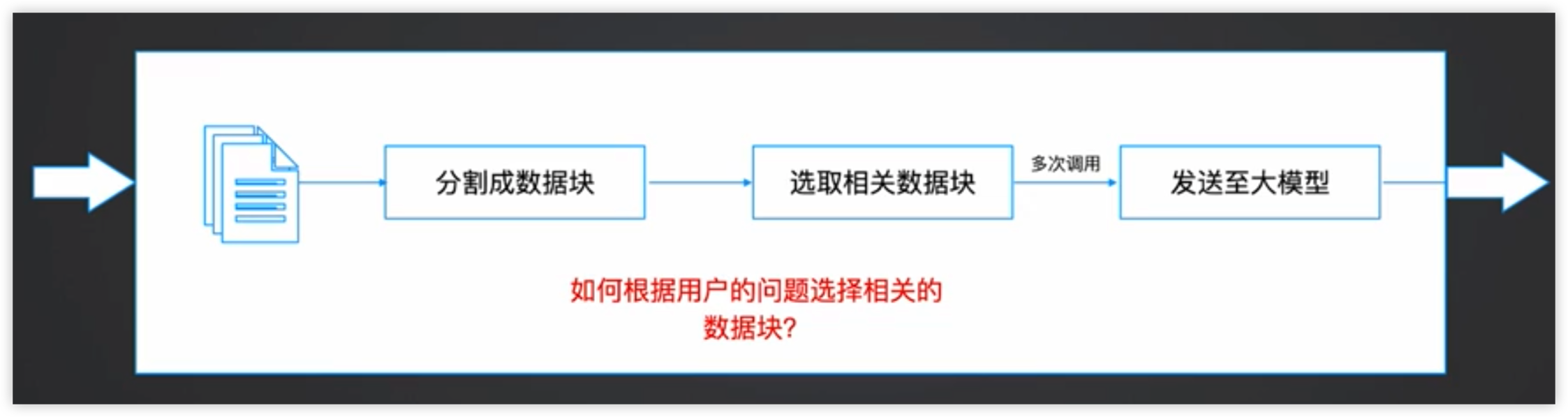
一种可能的处理方式关键词检索:通过Elaticsearch、Lucene等类似搜索引擎的方式,根据文本建立索引,通过关键词严格匹配到对应的文本内容。但是这种方式会丢失很多上下文的信息,会让相同语意的文本丢失。
更好的方法是让关键词检索变为语义检索
语义检索是一种基于文本内容和意义的信息检索方法,它试图理解查询和文档的语义,以便更准确地找到与查询相关的文档。
向量化(embedding)是将文本数据转为数值向量的过程。向量化后的文本可以用于计算文本之间的相似性,如余弦相似度、欧几里德距离等度量。这使得语义检索能够根据查询和文档之间的语义相似性来对文档进行排序和检索,从而提高检索的准确性和效率。
我们可以把字符块进行向量化,通过向量间的距离来求解这些向量之间的相似性。也就是说,语义越相近的向量,它的距离就越短。
参考阅读
Word2Vec相关的一些机器学习的理论
实现流程
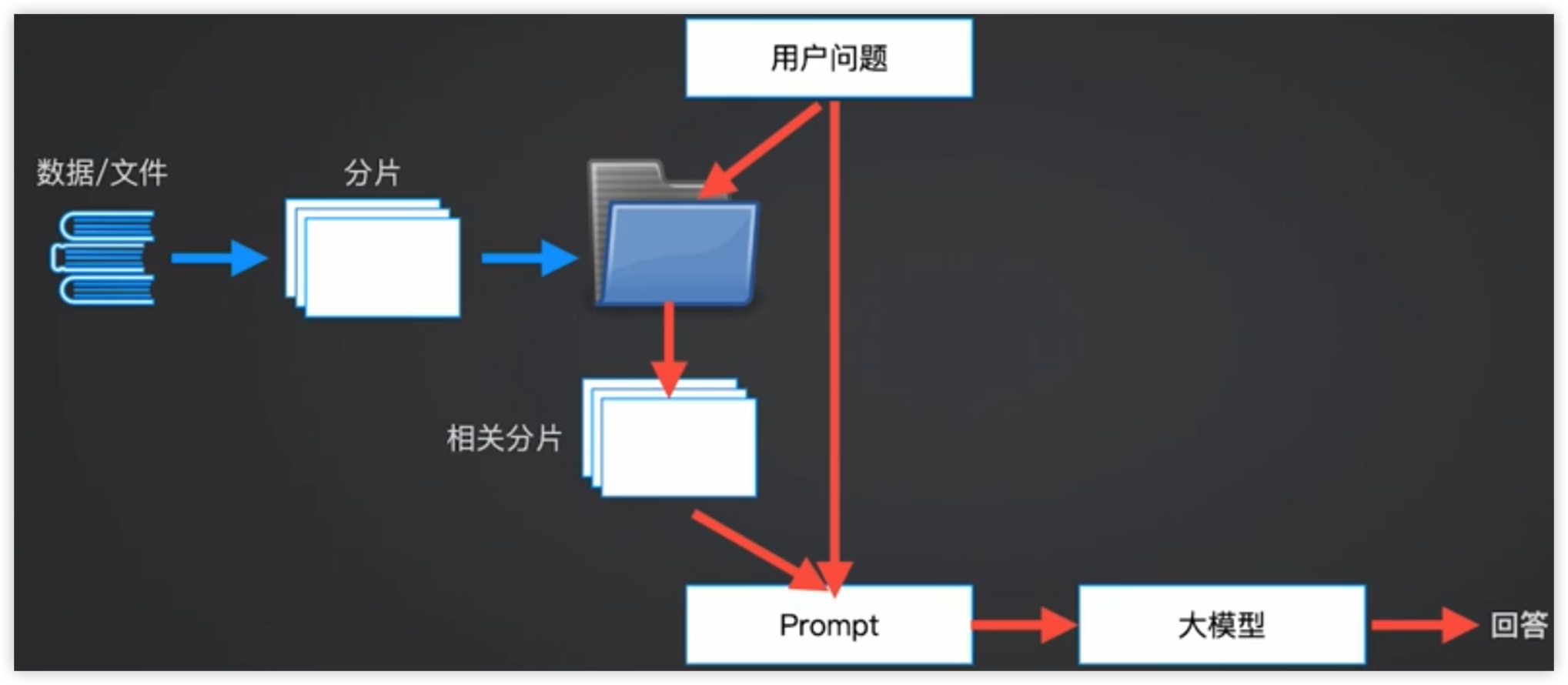
代码示例
1 | # 向量化简单示例 |
文本向量化
1 | from langchain.embeddings.openai import OpenAIEmbeddings |
向量检索
1 | def find_k_largest_indices(input_list, k): |
向量检索 + GPT
1 | import openai |
*也可以使用embedding模型辅助实现,embedding model使用nomic-embed-text
Ollama embedding model
https://ollama.com/blog/embedding-models
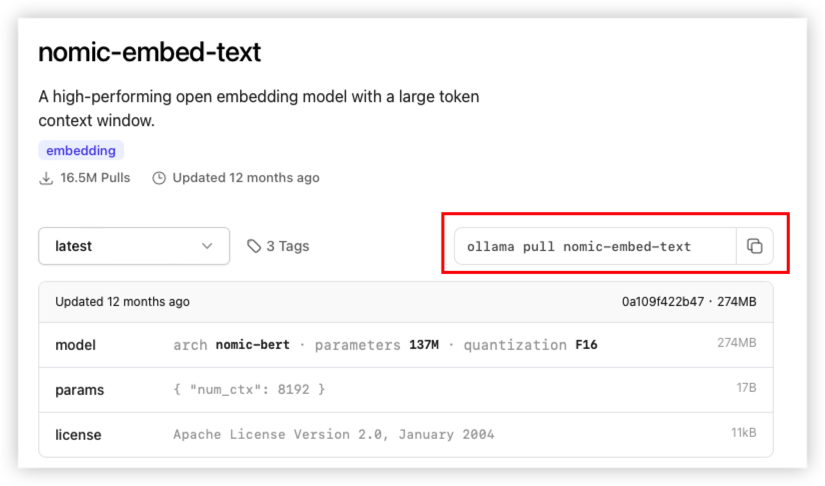
nomic-embed-text model
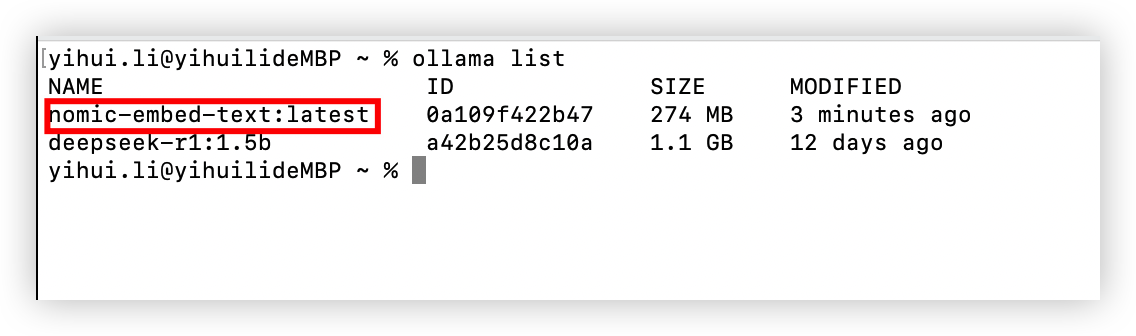
通过ollama安装模型
复制命令
在命令行安装

LangChain Retrieval
通过LangChain连接大模型和内部文本
上面使用了chroma向量数据库,在这一节配合LangChain使用实现分片向量化的整个工作流

LangChain Document Loader加载数据
支持CSV,文件目录,HTML,JSON,PDF,Markdown等多种格式
https://python.langchain.com/docs/integrations/document_loaders/
LangChain Retrievers
更好的文档分片工具
https://python.langchain.com/docs/integrations/retrievers/
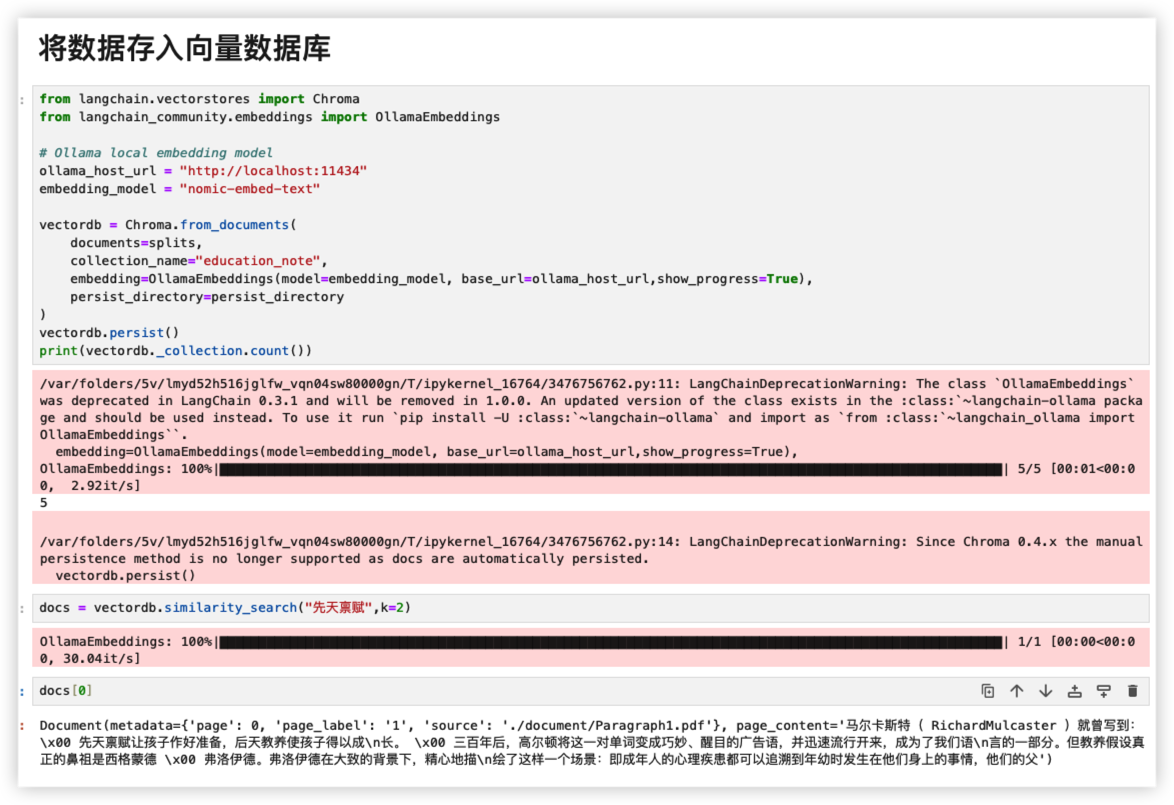
最后把分片好的数据embed到向量数据库
LangChain提供了RetrievalQA的方法直接查询向量数据库(Vectordb)
用户提问 -> 向量数据库检索 -> 构成新的prompt -> 大模型回答
这里使用md文档为例
1 | retriever=vectordb.as_retriever( |
search_type:根据场景选择适合的参数
- similarity:根据相似性查找,最多查找3个
- mmr(max marginal):找到三个最相似的,然后根据这三个数据库之间差别最大的,但是跟用户问题又有关联性的问题
1 | qa = RetrievalQA.from_chain_type(llm=llm, chain_type="refine", retriever=retriever, |
chain_type: 可选值 stuff / refine / map reduce / map re-rank
- 要根据企业内部的实际情况和数据特性,尽可能多地测试
- 适当做一些定制化的改动以满足需求
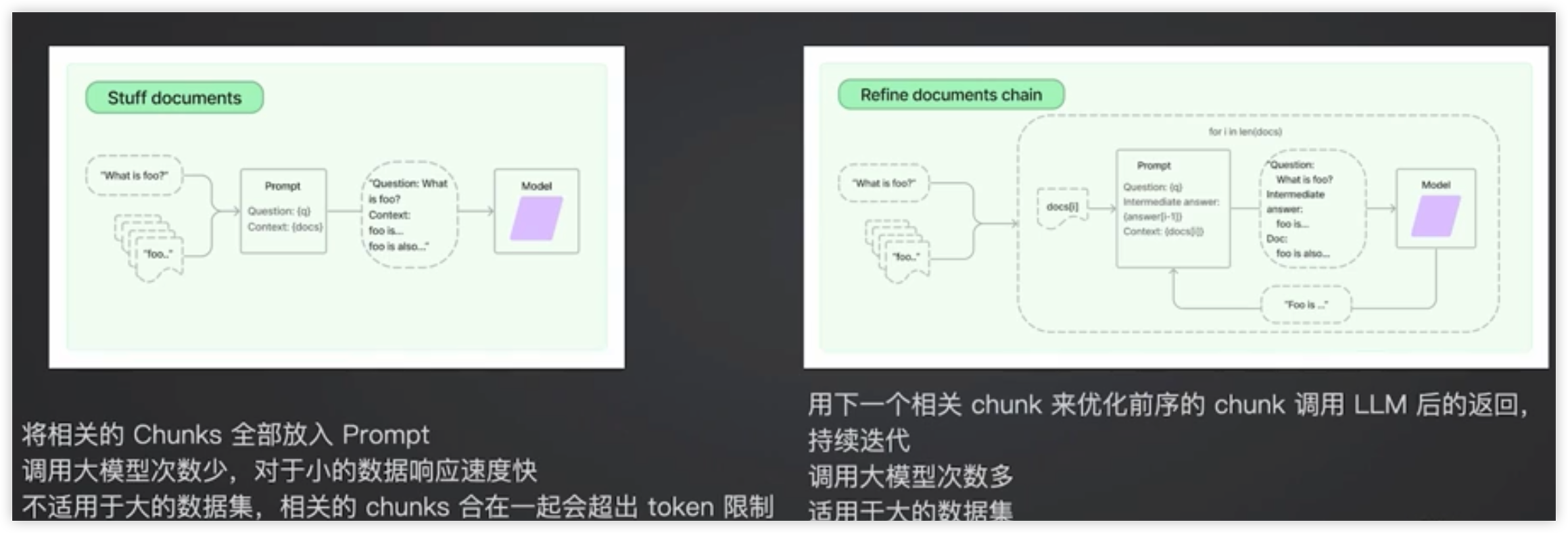
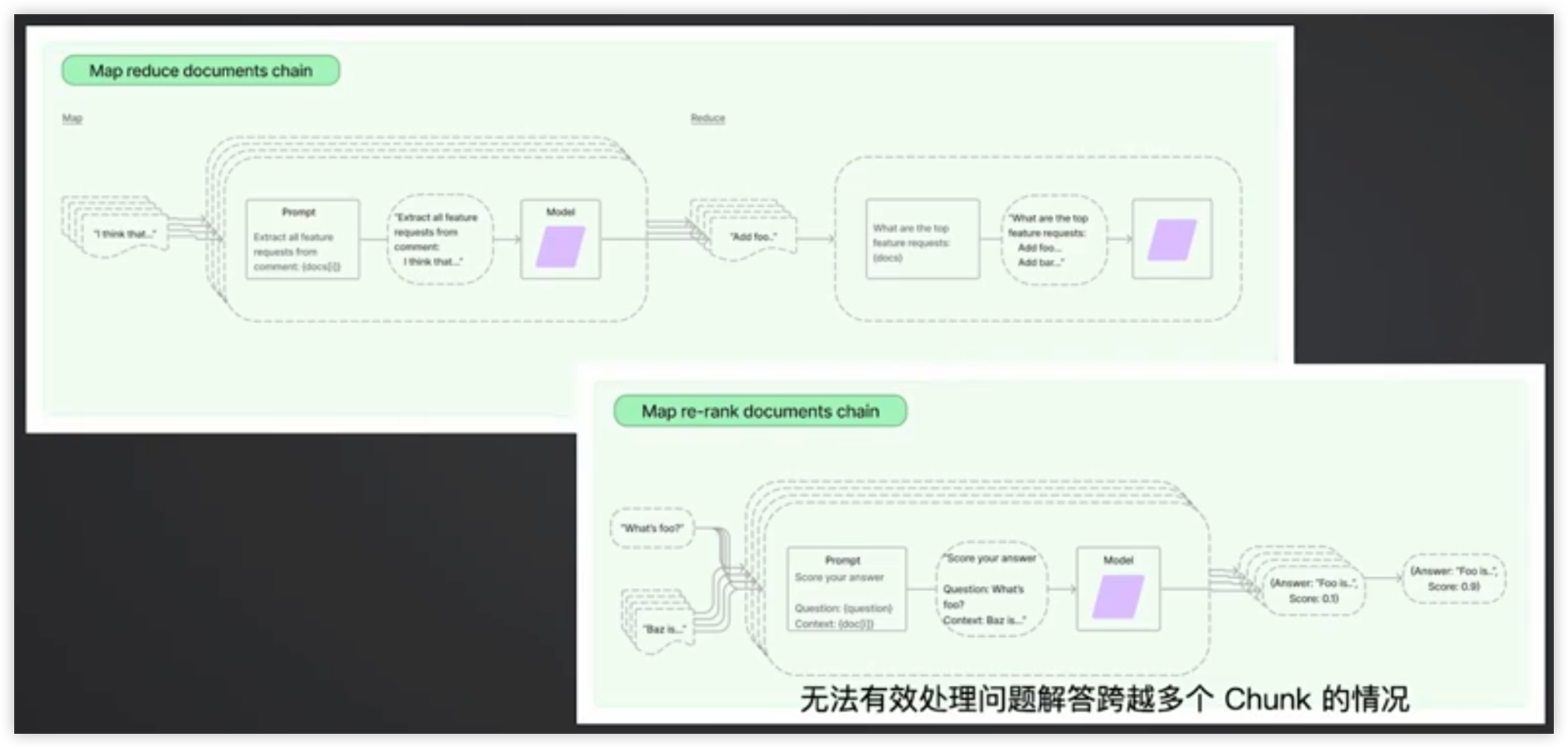
源代码
https://github.com/KaloSora/HelloGPT/blob/dev/code/gpt_langchain_retrieval.ipynb
参考阅读
构建多模态Chatbot
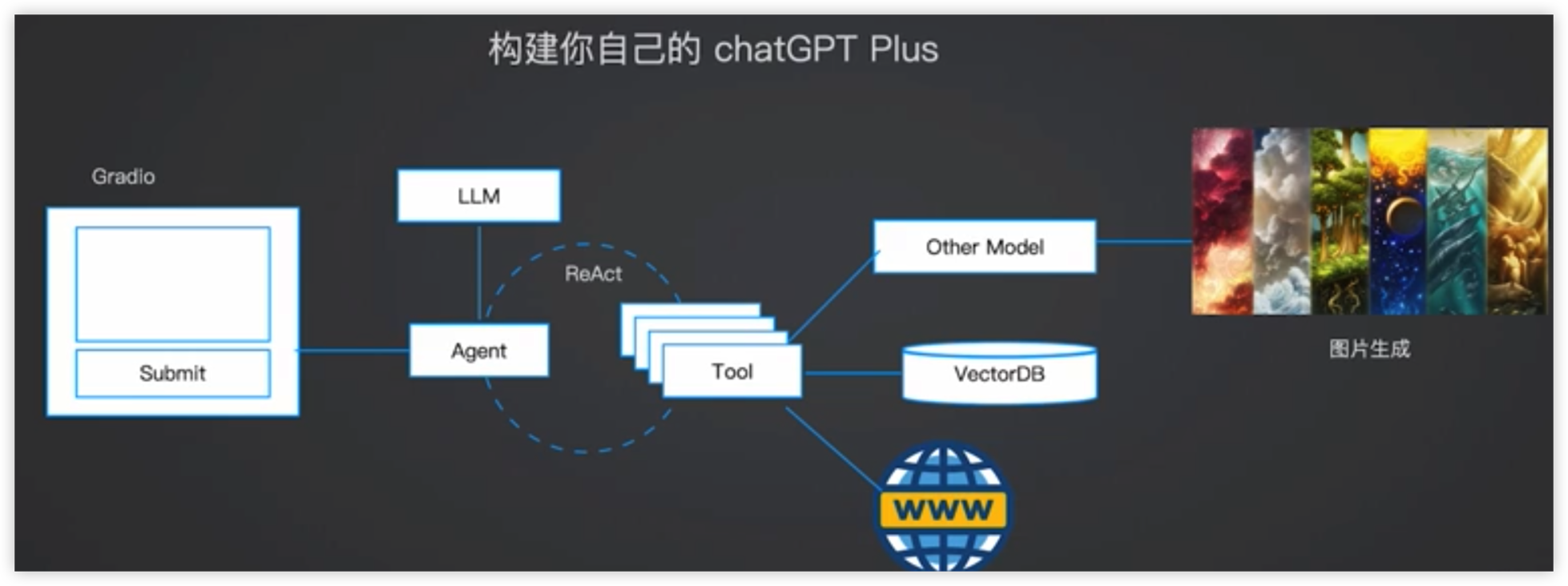
图形生成能力:openai可以使用DALL E2,或者是Stable Diffusion
Openai api示例
1 | import os |
Openai 代码示例
https://github.com/KaloSora/HelloGPT/blob/dev/code/gpt_all_in_one_example.ipynb