相同系列的文章
使用LLM辅助设计
可以让GPT生成多次不同的设计,最后结合自己的思考。
可以大大提高研发人员在面对陌生领域时的研发效率。
也可以让GPT帮助代码生成
- 根据注释、要求直接生成代码
- 根据代码生成测试(目前最准确,因为上下文只有代码,没有业务需求)
- 根据代码生成注释
- 在不同编程语言之间翻译
- 解释代码的运作方式
- 修改代码中的bug
- 其他
可以使用ReAct模式:GPT代码生成 -> GPT自测 -> GPTbug自动修改 (迭代 * N)-> 最终代码
需要满足以下条件
- ReAct过程中可以使用的方法
- 方法的输入简单(简单字符/JSON)
- 方法的输出是大模型可理解(不能只返回Error code,给出一个详细的自然语言描述)
源码
https://github.com/KaloSora/HelloGPT/blob/dev/code/gpt_llm_assist_design.ipynb
提高代码生成的可用性
使用ReAct pattern
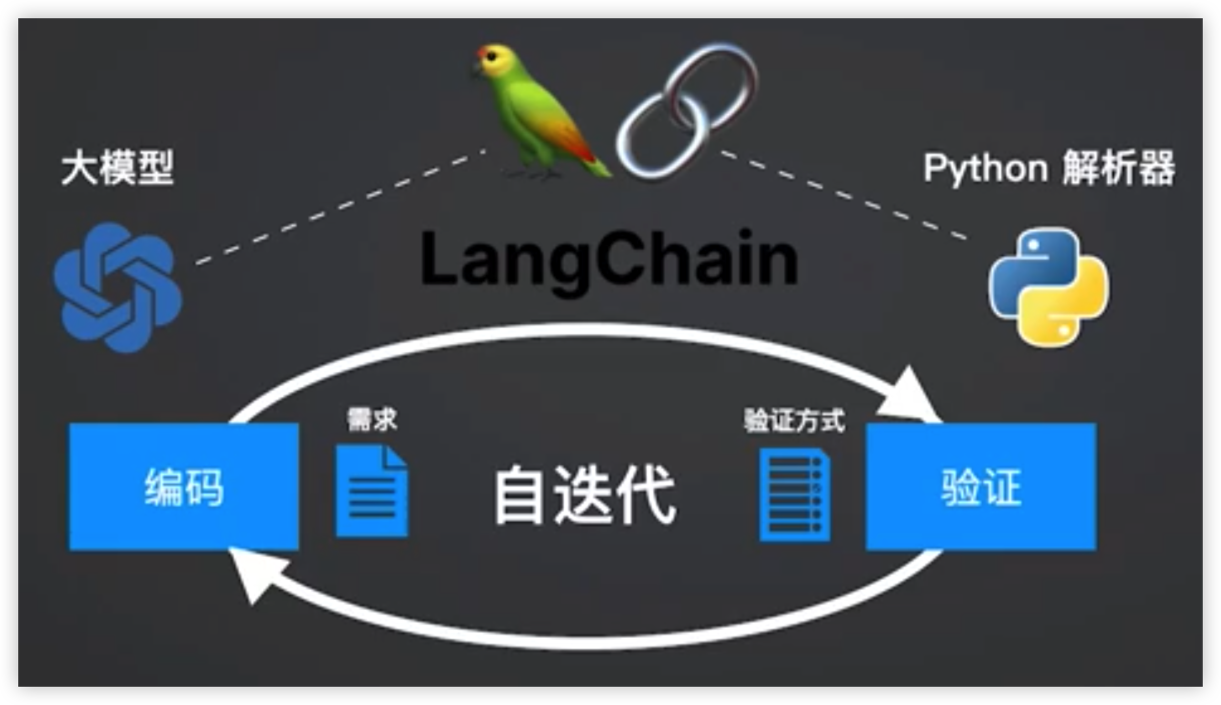
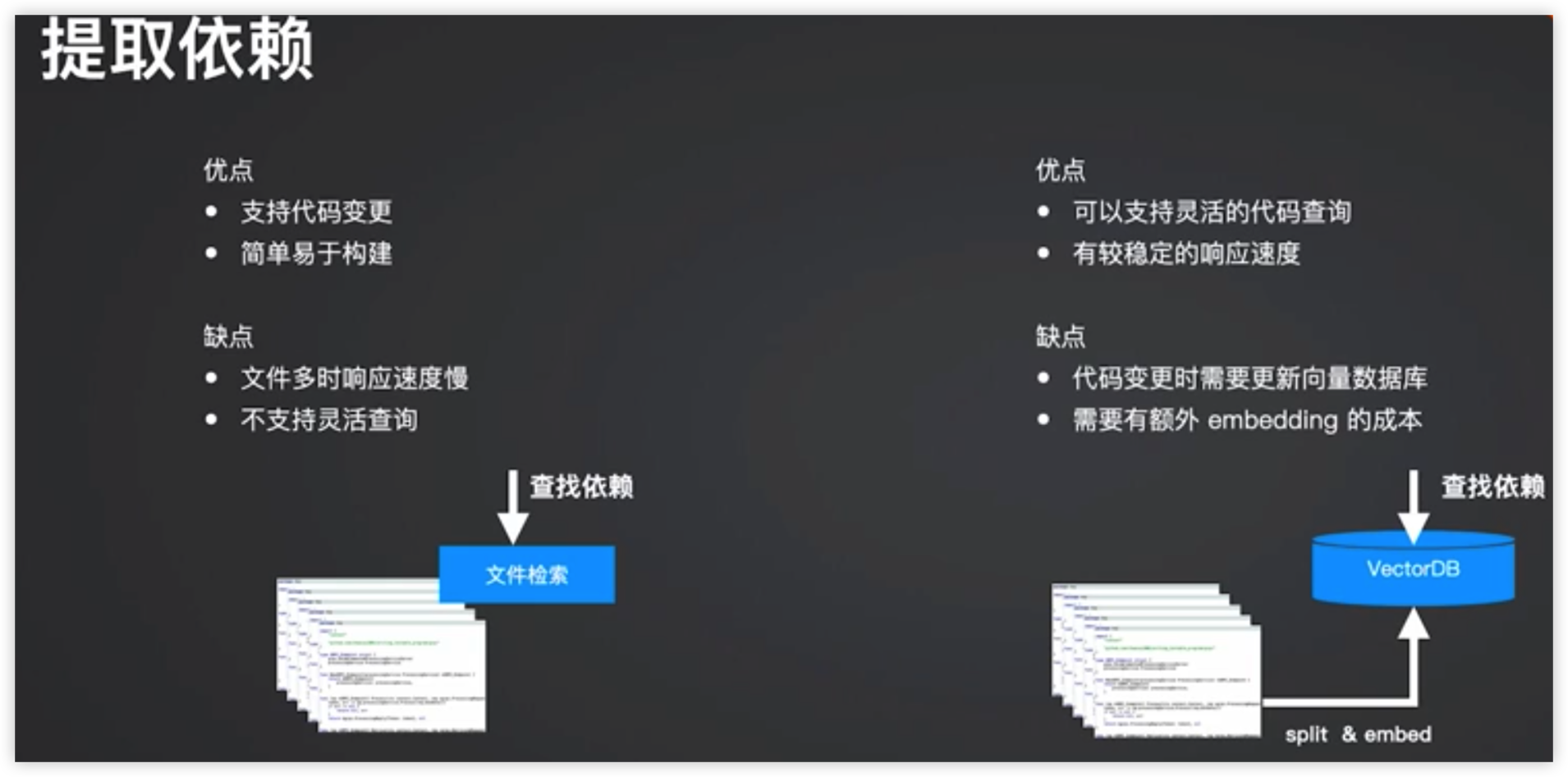
解决遗留代码依赖
外部推理:编写AST树遍历所有的依赖,整合到Prompt里传给大模型
大模型推理:大模型基于ReAct模式自己寻找测试依赖

方案比较
源码
https://github.com/KaloSora/HelloGPT/blob/dev/code/gpt_code_generation_example.ipynb
编写大模型友好代码
适合大模型生成代码的场景:
功能明确,定义清楚
- 通过规模较小的接口/方法签名来清晰定义
- 清晰的注释/Prompt的定义实现逻辑
通用功能
依赖简单
- 尤其是对自身遗留代码的依赖
大模型辅助运维和部署
利用大模型帮助Devops提高效率,赋能云原生实践
什么是云原生?
计算资源弹性伸缩:需要的时候快速的获得计算资源(几十秒至几分钟),不需要的时候把计算资源释放掉。计算资源允许横向拓展(增加集群)和纵向拓展(加强机器配置)
单物理机(大型机) vs 云原生
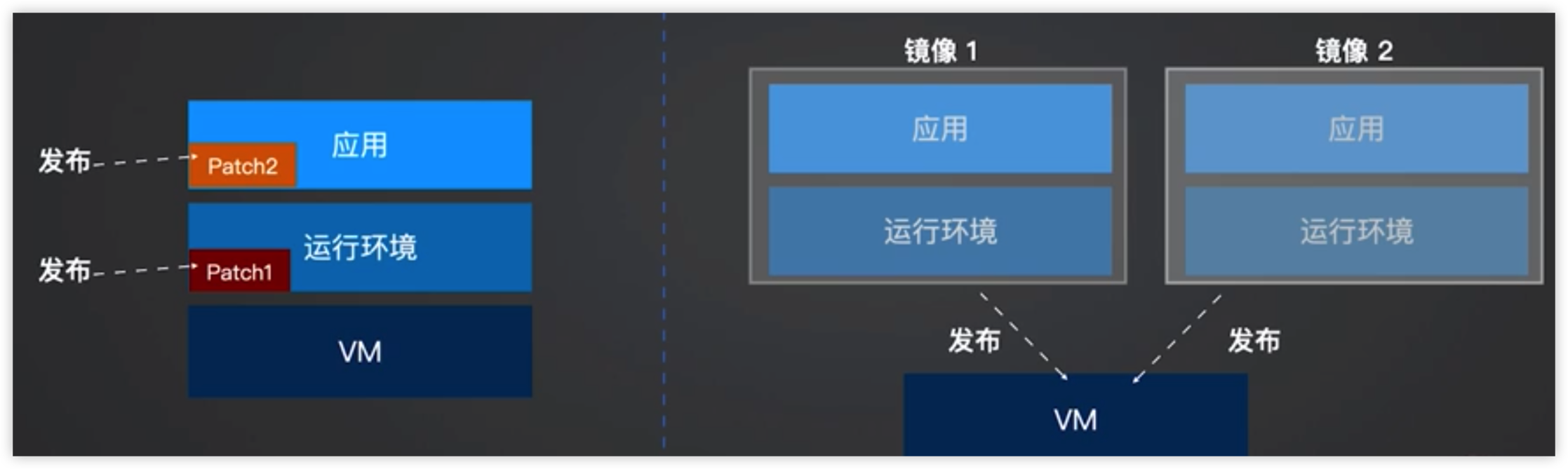
云原生实践中的CICD pipeline
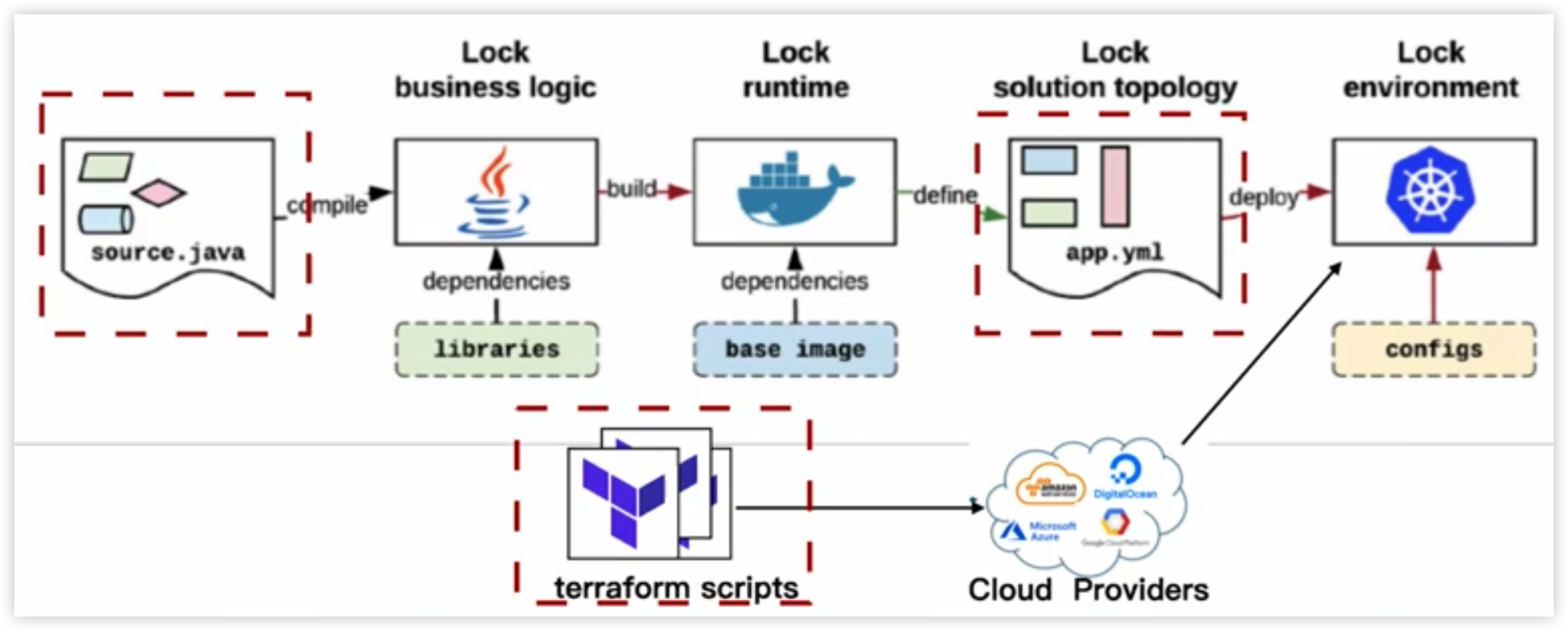
Terraform作为IaC工具,在云原生中发挥至关重要的作用
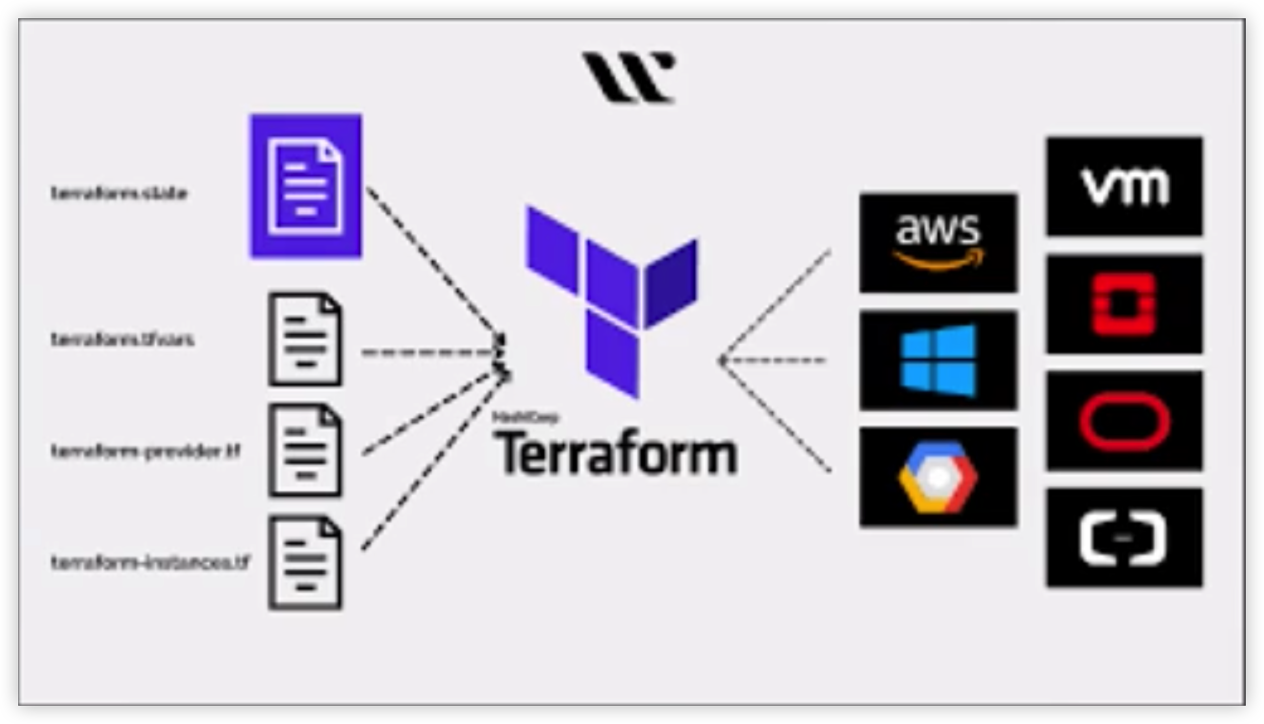
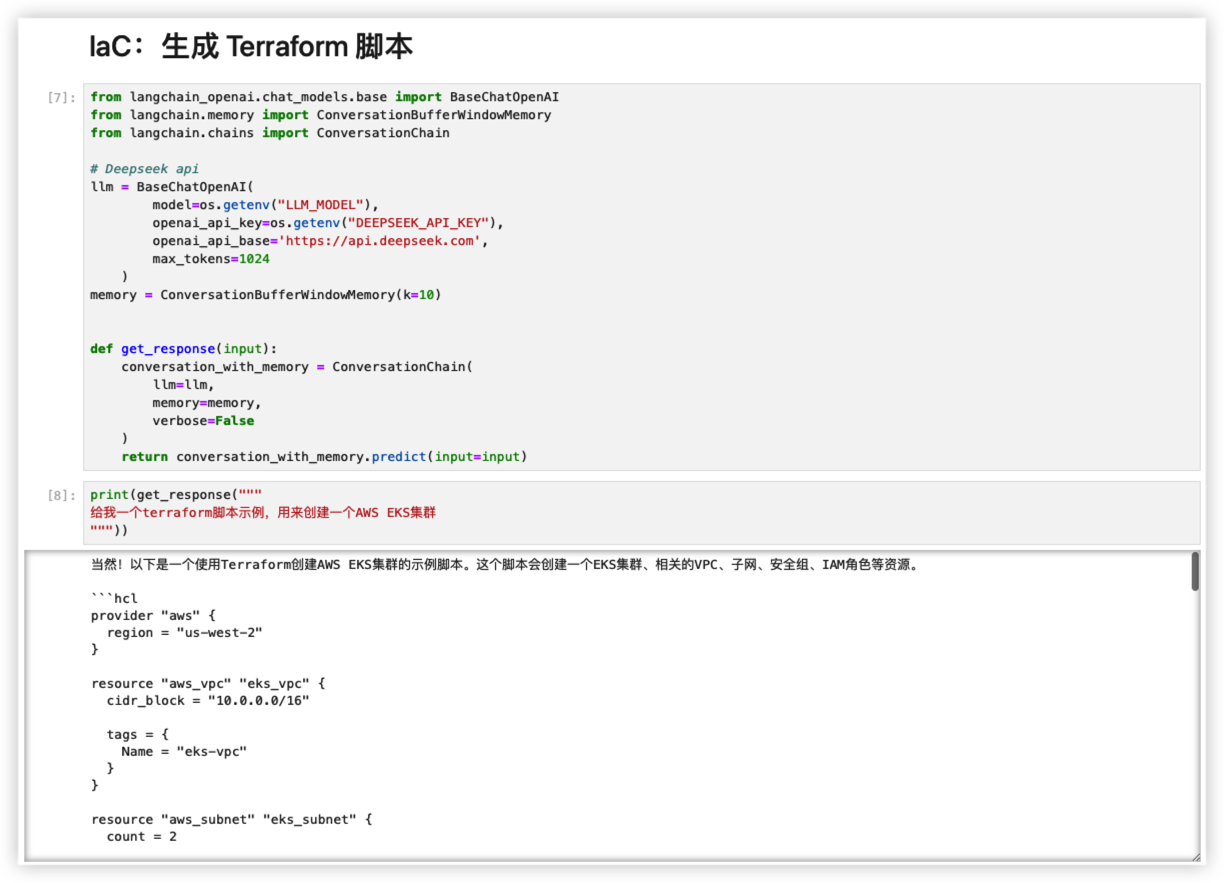
可以利用大模型帮助开发者生成terraform template,开发人员只需要修改部分内容即可完成开发。
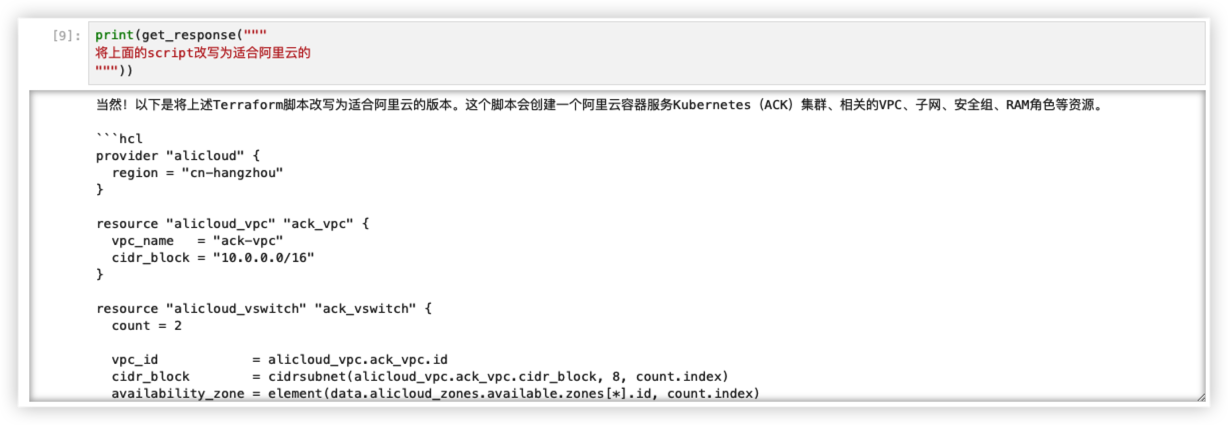
启用上下文记忆功能,让GPT把AWS云转换成阿里云的terraform格式
还可以利用大模型生符合Kubernetes最佳实践的部署配置文件
最佳实践的要求
- 部署的namespace为”service”
- 包含readiness及liveness probe
- 采用一个独立的 service account 运行
- 包含完美终止(graceful termination)配置
源码
https://github.com/KaloSora/HelloGPT/blob/dev/code/gpt_cloud_devops_example.ipynb
探索开源AI社区
利用Hugging Face开源社区中大量的开源模型,提升研发效率
Open source的模型统称为 pre-trained模型,可以直接使用它
Transformer Pipeline

Hugging Face的模型可以统一使用Transformer Pipeline调用。
如果要使用远程调用模型的方式,需要注册账号并创建API token
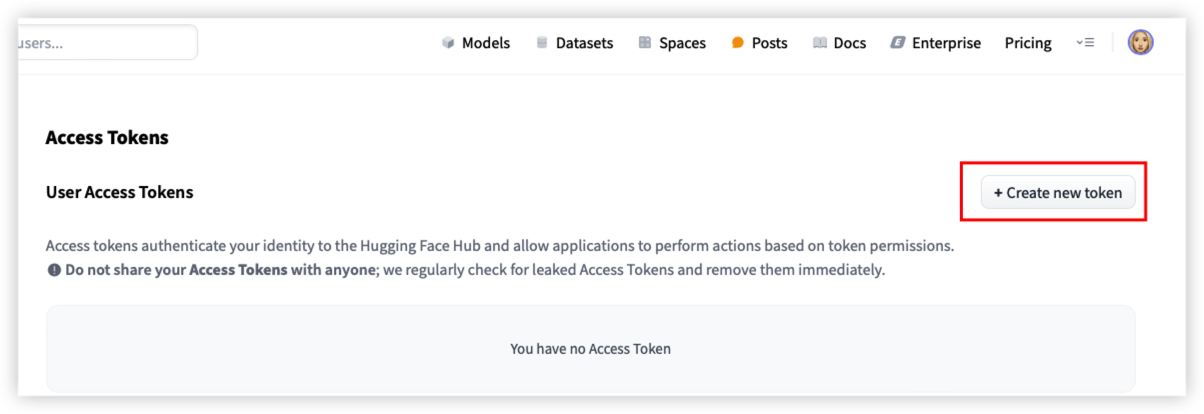
注意:Hugging Face需要安装tensorflow
Mac intel arm64会出现找不到安装包的情况

解决方法:安装Anaconda,并创建新的python运行环境
1 | conda --version |
从TFmacOS环境中启动jupyter notebook
源码
通过Hugging Face + Deepseek API 实现看图讲故事
或
LangChain + Hugging Face model
https://github.com/KaloSora/HelloGPT/blob/dev/code/gpt_hugging_face_example.ipynb
AI企业架构中的思考
企业内部文档处理
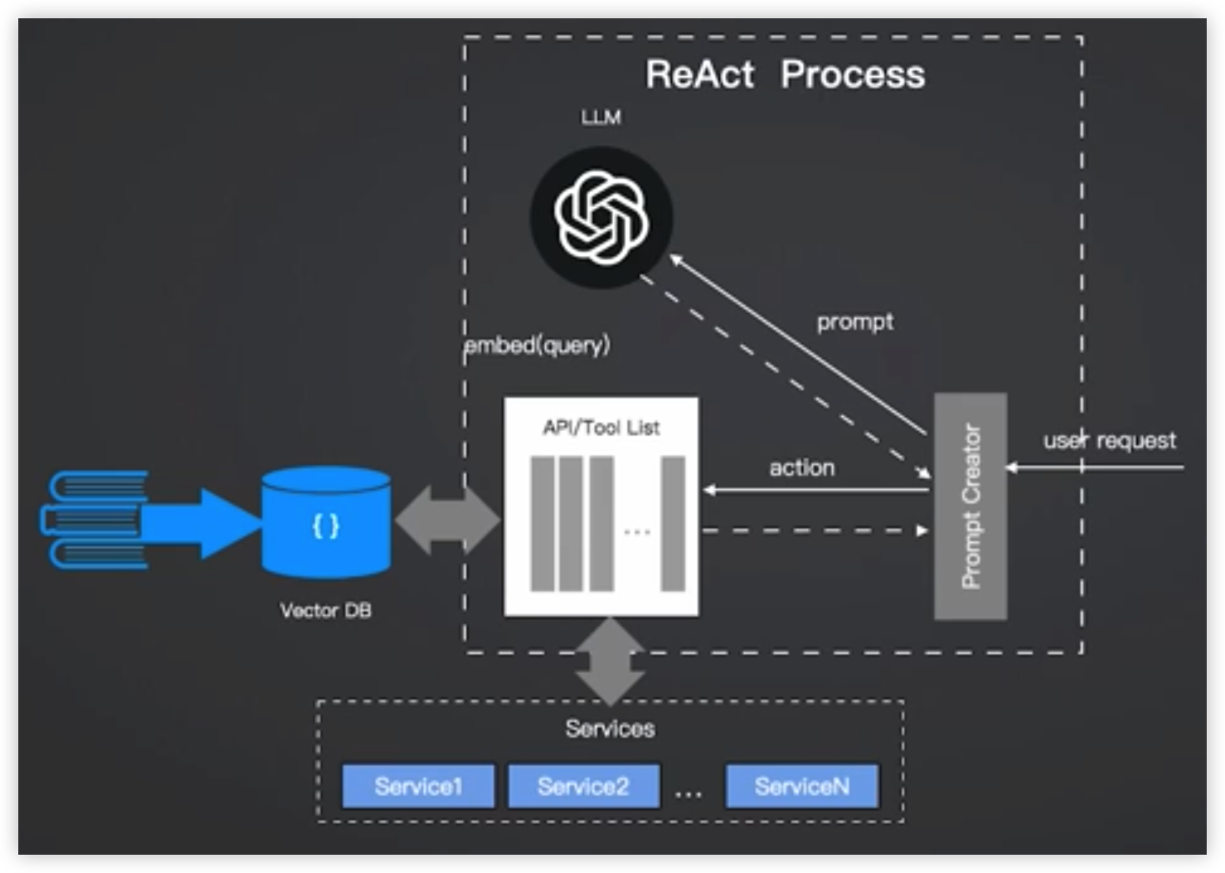
其他参考架构
- 使用
prompt validation防御提示词注入进攻
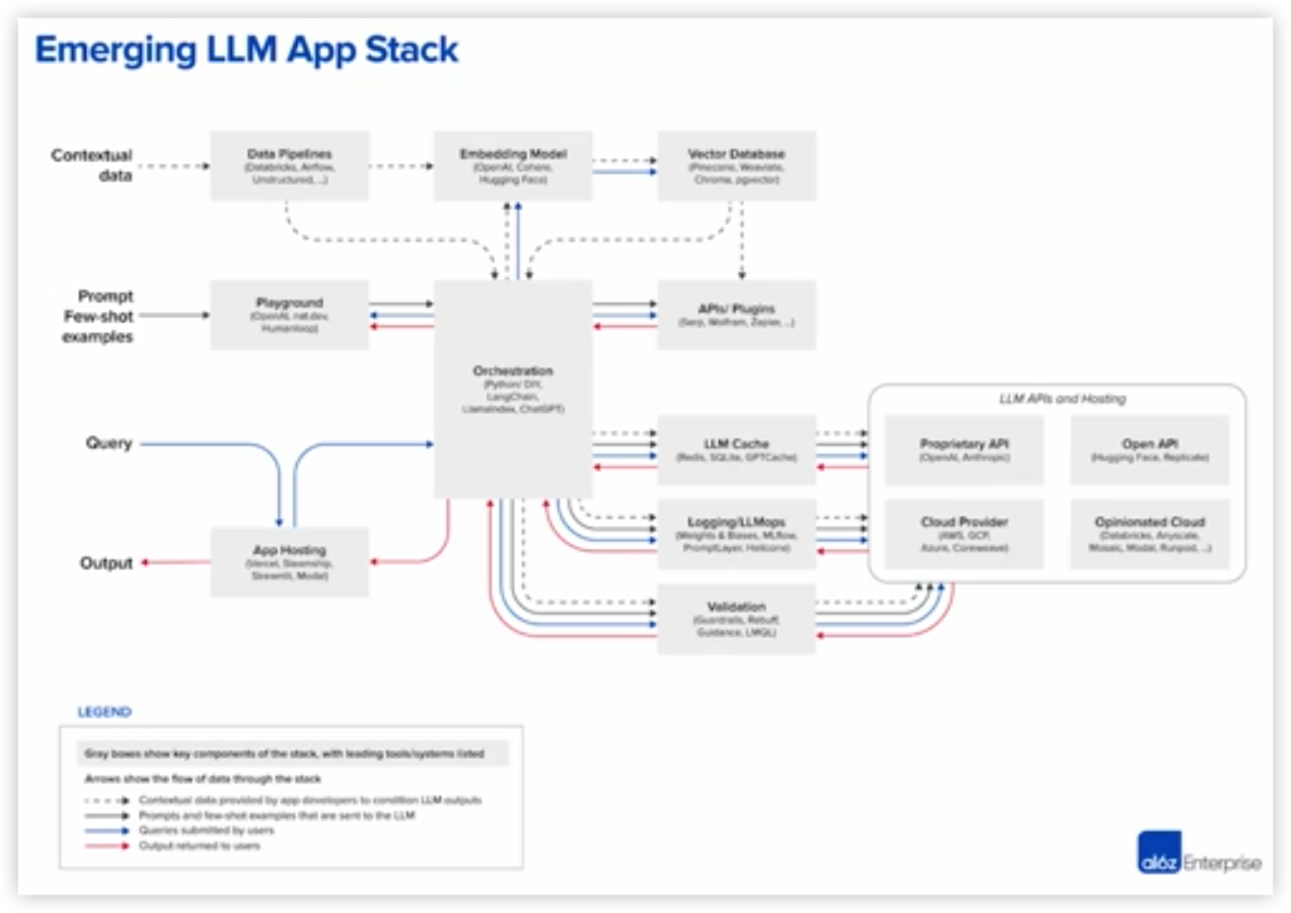
最后总结一下使用到的模型社区
Hugging Face
Ollama